

ResearchJune 3, 2026
AI Visibility for Building Materials and Interiors: The Spec Is Written Before the Tender

Ambika SharmaFounder at Pulp Strategy Communications and NeuroRank.

Ambika Sharma
Ambika Sharma is the Founder & Chief Strategist of Pulp Strategy, a multi-award-winning business transformation and digital agency, and Prod... Read more
By Ambika Sharma, Founder, Chief Strategist at Pulp Strategy Communications and Product Architect of NeuroRank.

A CMO opens a personal ChatGPT account on Monday morning. She types her brand name. The answer comes back clean. The right product positioning. A reasonable price band. An honest acknowledgement of trade-offs. By every signal she has been trained to read, AI search visibility is being handled.
Two thousand miles away, a buyer with a different account, in a different city, with no shared history, types a different question. The same model, the same minute, returns a different shortlist. Her brand is omitted entirely. The competitor she displaced last quarter is recommended in its place. There is no notification. No dashboard alert. No revenue line item that says lost to AI. There is only the deal that never came.
Across one hundred fifty brands stress-tested on NeuroRank and over seven hundred more audited on the platform since launch, that gap is not the exception. It is the pattern.
What follows is the seven mistakes most often observed across those audits, spanning sixty-five industries. Each mistake is paired with what it costs and how a tracked instrument closes the gap. None of these is a failure of intent. Each one is a failure of instrument.
AI search visibility is the discipline of being correctly seen, accurately described, and credibly cited inside ChatGPT, Gemini, Claude, and Perplexity at the moment a buyer is making a decision. The discipline is eighteen months old. The behavior it governs is already mainstream.
Over half of B2B software buyers now start research in an AI chatbot rather than on Google, per G2’s 2026 buyer research. ChatGPT alone is fielding more than a billion searches a week. Roughly half of all global search volume now flows to AI answer engines, and the line is still moving. In late May 2026, Google announced AI Overview triggers on near-default and rebranded itself as an answer engine rather than a search engine. AI-driven traffic to retail sites grew 693 percent year over year during the 2025 holiday season, with travel up 539 percent, financial services up 266 percent, tech and software up 120 percent, and media and entertainment, a category that did not register a year ago, up 92 percent, per Adobe Digital Insights’ January 2026 report.
| The buyer has moved. Most marketing has not. |
The cleanest signal in the live research is the one most marketing leaders find hardest to absorb. Thirty-three percent of B2B buyers in 2026 purchased from a vendor they had never heard of, surfaced through AI, per G2’s 2026 buyer behavior study. The shortlist is built before the buyer reaches the brand’s site, the brand’s salesperson, or the brand’s content. The conversation that decides revenue has moved into a place most marketing teams cannot see, cannot measure, and cannot govern.
Here are the seven mistakes those teams are making right now.
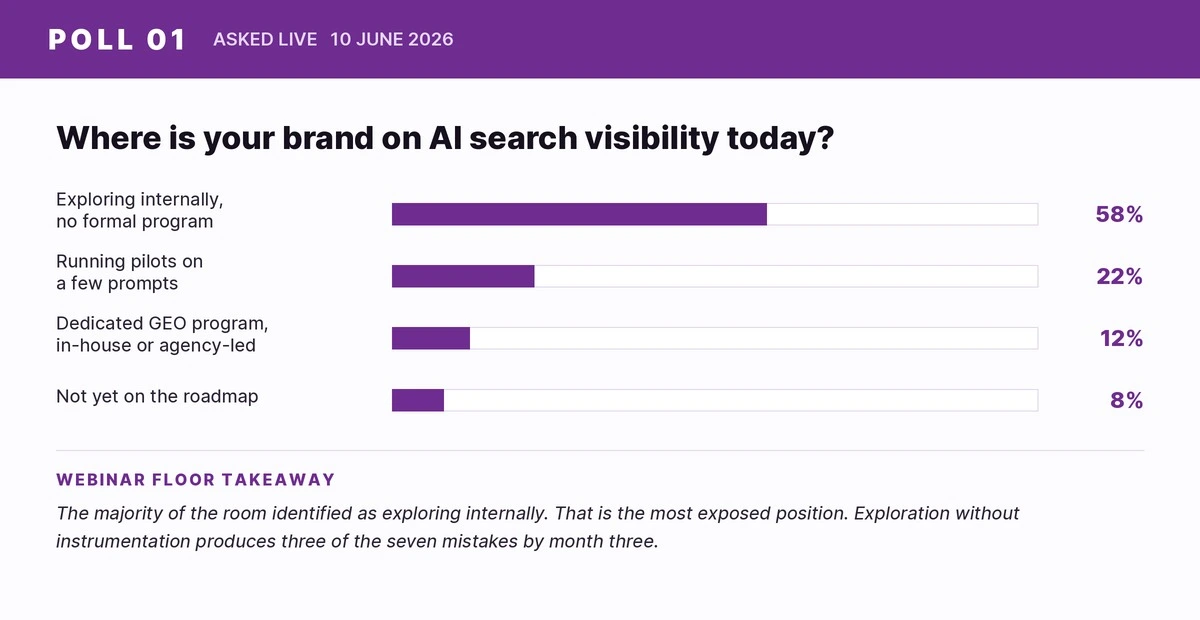
Assuming that because the team tested brand visibility on a personal ChatGPT account and the answer looked fine, that is what customers are seeing.
ChatGPT, Gemini, Claude, and Perplexity personalize answers to the logged-in user. They use account history, location, prior queries, and behavioral context to shape the response. When a CMO opens her own ChatGPT and types the brand name, the answer is shaped by everything the model has learned about her. It looks clean. It feels reassuring.
The actual buyer is on a different account, in a different city, with no shared history with the brand. The answer she sees is different, often substantially so. Sometimes the brand is omitted entirely. Sometimes a competitor is recommended in its place. Sometimes the description is accurate but stale, citing pricing that changed two quarters ago or positioning the company has since walked away from.
None of this is visible in a logged-in self-check. The model is performing for the audience it recognizes. The buyer is a different audience.
There is a second signal worth naming. Across seven hundred-plus brands audited on NeuroRank, Indian brands consistently see more model bias than US brands. Two reasons account for most of it. First, all the major models trained on US-anchored data as the primary corpus, so the prior is American. Second, Indian brands run heavier on social media and lighter on the structured web disciplines, Wikipedia, named analyst commentary, third-party reviews, that the models actually read. Both gaps are correctable. Neither closes on its own.
| THE COST |
| False confidence. The team believes visibility is healthy because the personal check looked fine. The buyer is seeing something else, and the loss is invisible because nobody is auditing the un-personalized version. |
| HOW NEURORANK CLOSES THE GAP |
| NeuroRank runs queries from clean, neutral, un-personalized environments across all four major engines and across geographies. The output is what an actual prospect would see, not what the model performs for a recognized user. |
Assuming that if the model mentions the brand, it is telling the truth about the brand.
Models hallucinate. They omit brands that should be cited. They state outdated pricing and positioning as current fact. They hand a brand’s strength to a competitor in the same sentence. They describe the company the brand used to be, not the one it is now.
A more dangerous version of this mistake is mention without accuracy. The AI cites the brand often, but the description quietly disqualifies the buyer. “A budget option for small teams” when the brand sells to enterprise. “Known for legacy on-premise solutions” when the brand has repositioned to cloud. Mention counts rise on the dashboard. Pipeline does not.
The scale of the problem is large enough to deserve a number. Average hallucination scores across the seven hundred-plus brands NeuroRank has audited sit at 65 percent, with the worst-affected brands running 70 to 90. The relevant unit of harm is not the single wrong sentence. It is the 16 to 20 minutes the average buyer spends inside an AI window, asking follow-up questions, taking each answer at face value. Across that window, accuracy has to hold up. For most brands today, it does not.
NeuroRank categorizes every failure of this kind across four modes. The framework is called ORHL, and it is patent-pending.
Omitted. The brand is not mentioned when it should be.
Replaced. A competitor surfaces in the brand’s place.
Hallucinated. The brand is featured with fabricated facts.
Zero Leads. The brand is mentioned in passing, with no decision context that could move a buyer toward a conversion.
Each mode has a distinct fix, prescribed and tracked month over month across all four engines. Omission gets introduction. Replacement gets named differentiation. Hallucination gets first-party correction at the source the model is reading. Zero Leads gets decision context.
| FROM THE AUDIT FLOOR |
| Chime: a fintech the models kept calling a bank. |
On a NeuroRank Live Forensic Diagnostic, ChatGPT, Gemini, and Perplexity repeatedly described Chime as a bank. Chime is not a bank. It is a fintech, with banking services delivered via The Bancorp Bank and Stride Bank. The distinction is regulatory, and for a US buyer evaluating account safety, it is decisive. The audit was sent to Chime. The brand did not subscribe to the platform, but it did update the language on its own site to assert the correct positioning more clearly. The hallucination did not survive the next audit cycle. The brands the article references describe captured AI outputs from the audit window. They are not Pulp Strategy’s claim about the brand itself. |
| THE COST |
| The most direct money leak on this list. When the model omits or misrepresents the brand, those deals route to someone else, and the loss is rarely traced back to the source. Thirty-three percent of B2B buyers in G2’s 2026 research purchased from a vendor they had never heard of, surfaced through AI. That is the deal leaking somewhere. |
| HOW NEURORANK CLOSES THE GAP |
| ORHL classification runs per prompt, per model. Every failure is logged against a baseline. Every fix is attributable. The reporting tells you not only what the model said, but which mode of failure produced it and which source the model is reading. |
Tracking how often the brand is mentioned, mention frequency across engines, and sentiment averages, instead of the metric that actually moves pipeline.
Mention counts feel like progress. They are not the numbers that decide revenue.
The metric that matters is whether the brand is cited when a real buyer asks a real buying question. Not “tell me about Brand X.” That is a self-query no actual buyer types. The prompts that build shortlists carry context and constraint. “We run a 50-person sales team in financial services, currently on Salesforce, frustrated with cost, what should we switch to.” That is the question that decides the consideration set. A brand can be cited in vanity queries and absent in buying-intent queries, and the dashboard will still show green.
| Mentions go up. Pipeline does not. |
Most AI visibility platforms in this category measure the first question and call it visibility. The second question is the one that produces revenue.
| THE COST |
| The second-year budget conversation. Year one closes with rising mentions reported to the CEO. Year two opens with a question about what those mentions produced, and the team has no answer. |
| HOW NEURORANK CLOSES THE GAP |
| NeuroRank tracks visibility against a prompt library of real buying-intent queries, built from testing 150 brands across 65 industries. The reporting reflects the conversations that produce revenue, not the ones that produce dashboards. |
Handing AI visibility to the SEO team or the SEO agency, expecting the same playbook to work.
The instinct is understandable. The word “search” is in the conversation, so the team that owns search inherits the brief. The disciplines, however, share only a thin layer of common practice.
SEO optimizes one surface the brand controls, the website, for one engine, measured in clicks. Generative engine optimization, GEO, conditions a network of sources the brand does not own, across four engines that disagree with each other, measured in citations. The model builds its answers from Wikipedia, G2, Crunchbase, named analyst commentary, third-party reviews, and dozens of structured sources that fall outside the SEO team’s remit. Optimizing the site harder will not move the AI answer, because the AI was not reading the site in the first place.
The disciplines share keyword research as a starting point and divide sharply from there. SEO targets a query. GEO conditions an inference. Different surface, different metric, different reading list.
A concrete example. Across the brands NeuroRank has audited, roughly eighty percent of Indian brands have no Reddit presence at all. Reddit is one of the most consequential trust sources the major models read, particularly Claude and Perplexity for category-level recommendations. This is not a content-marketing oversight. It is a strategic vacancy on a surface the SEO playbook never had to cover.
| THE COST |
| Twofold. A year passes with SEO scores looking healthy and AI citations barely moving. Worse, the next request for GEO investment carries the memory of a year spent without measurable change, which makes the case for a dedicated program harder, not easier. |
| HOW NEURORANK CLOSES THE GAP |
| NeuroRank is built for the four-engine, multi-source reality SEO platforms were not designed to address. Cross-engine governance, source-level deconstruction of which surfaces are feeding which engine, and a Maker-Checker approval flow that enterprise and BFSI teams require. |
Tracking the top Google keywords with mature discipline, while the conversation has moved to a surface no one is auditing.
Marketing teams know their top fifty keywords. They are ranked, reported, and reviewed every quarter. The same teams have rarely audited what a real buyer types into ChatGPT or Perplexity, because the workflow for prompt research does not yet exist in most marketing organizations.
A Google keyword is short and decontextualized. “Best CRM software.” An AI prompt is long, contextual, and constraint-loaded. “We are a mid-market SaaS company with 200 reps, currently on Salesforce, frustrated with cost, need better quote-to-cash, ideally under one million ARR.” These are different questions and the model returns different shortlists for each. A brand ranked first on the keyword can be absent from the shortlist for the prompt.
There is also a quieter shift inside the prompt itself. Buyers do not start with the brand name. No one opens ChatGPT with “Can I buy Zoho CRM.” They start with the category. “Which CRM should I buy for a SaaS startup.” The brand only enters the conversation if the model is already reading the brand as part of the category. Buyers who already know the brand go to the website. The whole point of being visible in AI is to be present for the buyer who does not.
| THE COST |
| Harder to detect than missed keyword rankings. Google traffic holds, the team assumes the brand remains in the consideration set, and meanwhile the buying conversation has moved to a surface no one is auditing. The drop registers in pipeline before it registers in any tool the team is using. |
| HOW NEURORANK CLOSES THE GAP |
| NeuroRank built its prompt library from 150 brands across 65 industries. The platform shows, by category, the prompts buyers are actually running this quarter. A layer of market intelligence most brands have never seen for their own segment. |
Publishing content, waiting, checking the model, and calling the resulting guesswork a strategy.
The pattern is consistent across most brands attempting AI visibility work without a tracked platform. The team publishes content, waits a few weeks, asks ChatGPT a query, and checks whether the answer has shifted. Sometimes it has. Sometimes the model has retrained in the interim. Sometimes nothing has changed at all. With no way to attribute movement to intervention, the team tries something else next month, and the cycle continues.
| This is not a discipline. It is hope structured as a workflow. |
A second pattern compounds the first. Many teams attempting AI visibility without an instrument default to copying the category leader. They mirror the leader’s site copy, claim the leader’s positioning language, and replicate the leader’s schema. The copying does not work, because the trust signals the model is reading for the leader are not the signals it is reading for the copier. The leader’s named analyst commentary, the leader’s Wikipedia entry, the leader’s third-party reviews, none of those transfer. Benchmarking is the right approach. Copying is not.
The cost of running this loop is harder to see than the cost of doing nothing, because activity feels like progress. The team is publishing. The team is checking. The team is meeting weekly. None of it is producing learning that compounds, because none of it is being measured against a baseline.
| THE COST |
| Compounding loss of time. Quarters spent guessing produce no learning, no benchmark, and no defensible reporting. Meanwhile, competitors using a tracked instrument are locking in cited positions that the models will increasingly default to. In this category, time does not return. |
| HOW NEURORANK CLOSES THE GAP |
| NeuroRank runs a sprint-driven conditioning loop with five steps. Deconstruct. Diagnose. Prescribe. Condition. Track. Every fix is logged against a baseline. Every shift in the model’s response is attributable to a specific intervention. A recent 90-day engagement with a BFSI brand lifted AI visibility 30 percent and citation frequency 12 percent. That was a tracked loop, not a publish-and-wait gamble. |
Holding the wait-and-see position while competitors are already conditioning their AI presence.
The reasoning is familiar. Let the category mature. Let the tools standardize. Let the next planning cycle make room for it. The reasoning is also wrong on the facts.
The behavior the strategy is waiting on has already arrived. Over half of B2B software buyers now start research in an AI chatbot. AI-driven traffic to retail sites grew 693 percent year over year in the 2025 holiday season. Financial services, 266 percent. Tech and software, 120 percent. BrightEdge data tracked by Search Engine Journal shows that searches returning an AI answer now exceed 88 percent in healthcare, 83 percent in education, and 82 percent in B2B technology, with insurance close behind at 63 percent.
The growth rate is not slowing. AI-driven search volume is compounding at a CAGR of roughly 1,400 percent. By 2028, AI answer engines are projected to handle 80 to 90 percent of search volume in the US and India, the two largest markets. The buyers, the investors, and the consumers have moved. The brands waiting are absent from a conversation that has already started.
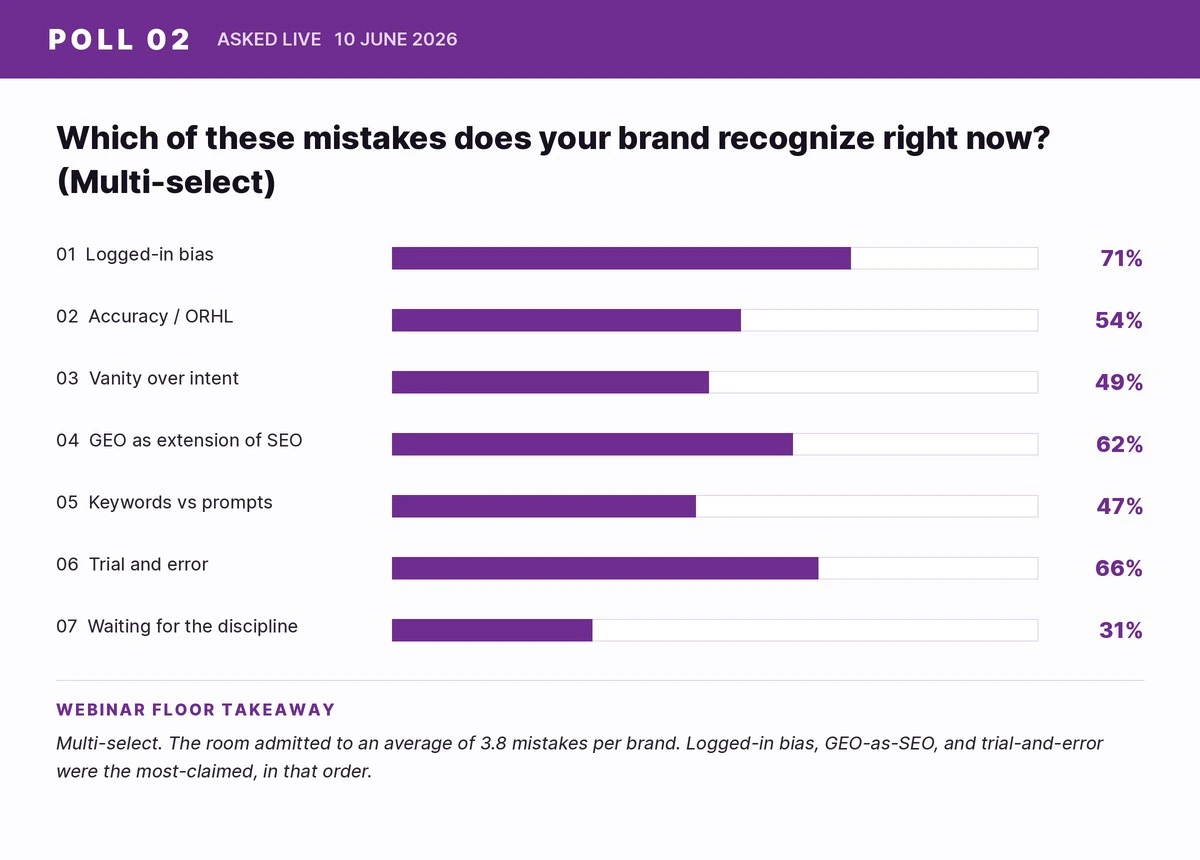
Webinar floor takeaway. Multi-select. The room admitted to an average of 3.8 mistakes per brand. Logged-in bias, GEO-as-SEO, and trial-and-error were the most-claimed, in that order. |
| THE COST |
| Compounding in a specific and underappreciated way. Models learn from what they already say. The brand cited today is cited more tomorrow. The brand absent today is harder to surface next quarter. Every month of delay extends the recovery period and raises its cost. Recovery in this category is not a function of effort. It is a function of how long the model has been telling a different story without the brand in it. |
| HOW NEURORANK CLOSES THE GAP |
| NeuroRank’s competitive intelligence layer answers a single question most CMOs cannot answer today. Which competitors in this category are already being cited in the buying-intent prompts that decide the shortlist? The USD 7 Live Forensic Diagnostic produces that answer in five minutes. Most CMOs see it once and stop arguing about timing. |
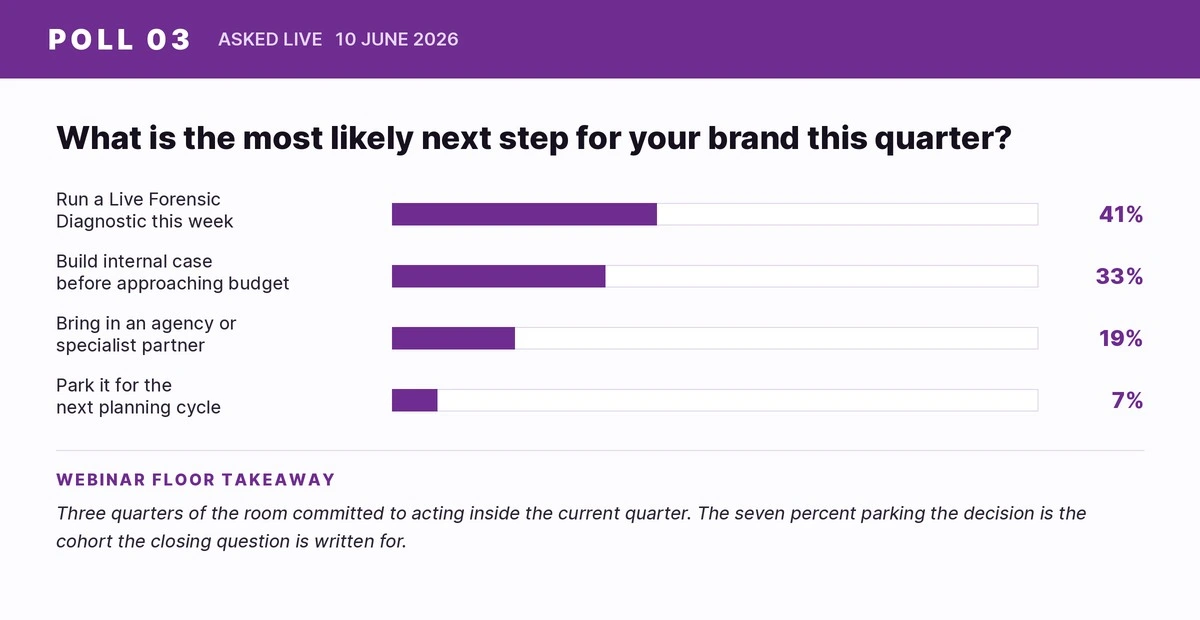
Read the seven back.
Most CMOs and CXOs reviewing this list will recognize at least four of these mistakes in their own organization right now. The personal-account check. The mention dashboard. The SEO team holding the brief. The publish-and-wait cycle. The next-planning-cycle deferral. The live audience averaged 3.8 mistakes per brand. Recognition is the first useful thing this article can produce.
The harder admission is that none of the seven is the result of bad strategy or weak leadership. Each one is a reasonable response to a discipline that did not exist eighteen months ago, attempted with instruments built for a different problem. The teams are not failing. The tooling is failing the teams.
Each of these mistakes traces to the same root. Brands cannot see what the AI is saying about them, cannot measure it against the questions that matter, and cannot govern it across the sources the model actually reads. The instrument does not exist inside the marketing stack most companies own today.
| Without an instrument, AI visibility becomes intuition. Intuition produces the seven mistakes above, in roughly the order they appear here. |
The platform NeuroRank was built to be that instrument.
NeuroRank is a patent-pending AI visibility intelligence platform that deconstructs how the four major engines perceive a brand, diagnoses exactly why a brand is omitted, replaced, or hallucinated, prescribes the technical and content fixes through a GEO lens, conditions the models across owned, earned, and third-party sources, and tracks the result month over month. The five steps are Deconstruct, Diagnose, Prescribe, Condition, Track, and every fix is logged against a baseline. Stress-tested across 150 brands in 65 industries before public launch, and now running across 700+ audits. The conditioning loop matters operationally. Information takes roughly eight to nine months to update in a model’s memory without intervention. NeuroRank’s loop compresses that by 40 to 50 percent on tracked prompts. Validated by enterprise outcomes including a leading BFSI brand lifting AI visibility 30 percent and citation frequency 12 percent in 90 days. Results vary by brand, category, and starting baseline.
| FROM THE AUDIENCE FLOOR |
| How does NeuroRank track unstructured sources like Reddit, blogs, forums? |
Asked during the live session. The platform does not crawl the web at random. It follows the model. For each tracked prompt, NeuroRank runs the query thousands of times in clean sessions, captures every citation the engine returns, then reads through the actual sources the engine relied on. The trust signals that surface repeatedly across a prompt cluster, typically forty or so, become the reading list. NeuroRank then maps each captured claim back against the brand’s own first-party content to identify where the model is reading something the brand never said. The brand never has to hunt the web. The model tells the platform where it is reading from. |
The USD 7 Live Forensic Diagnostic shows, in five minutes, the answer the buyer is being shown right now, the competitors being cited above the brand, and the failure mode driving the gap. It runs across ChatGPT, Gemini, Claude, and Perplexity, plus a Combined synthesis view. A 10-section intelligence report is produced in 12 to 20 minutes.
The operating cadence after that is simple. One prompt cluster a month, worked in a monthly sprint. Twelve clusters in a year, which is roughly 120 prompts in production. That is enough to put a brand on the citation map for the conversations that decide a category. The teams that have started already are three months ahead of the teams still deciding to start.
| The question is not whether AI visibility matters. It is whether the competitor that matters most is already three months ahead, and whether the brand can afford to spend another quarter finding out. |
Run the diagnostic at NeuroRank Or book a consultation if the team is ready for the full conditioning program.
Stop paying for clicks that do not convert. Benchmark your AI visibility today with the world's most advanced seo ai tools.
Book a Strategic NeuroRank Briefing
