


BlogJune 4, 2026
GEO Strategy After Google’s AI Mode: The Click Contract Is Dead

Ambika SharmaFounder at Pulp Strategy Communications and NeuroRank.
Ambika Sharma
Ambika Sharma is the Founder & Chief Strategist of Pulp Strategy, a multi-award-winning business transformation and digital agency, and Prod... Read more
Logged-in bias, Indian brand recommendations, and what audits across 700+ brands actually show
By Ambika Sharma, Founder, Chief Strategist at Pulp Strategy Communications and Product Architect of NeuroRank

Missed the Live Session? Watch the Recording - https://www.youtube.com/watch?v=aUZSJWsn52k
On 13 May 2026, NeuroRank ran the second webinar in its enterprise AI visibility series. The thesis: every CMO who has checked their brand on ChatGPT or Gemini has done so while logged in, which means AI personalized the answer against them. The dashboard says you are visible. AI says something different to your actual customer. This article covers the dashboard-lie thesis, the structural bias against Indian brands surfaced across 700+ brand audits, what 130 enterprise leaders told us in earlier polls, and the eight questions the audience asked during this session.
Most enterprise CMOs measure AI visibility on their own logged-in ChatGPT, Gemini, or Claude accounts. AI personalizes against the person checking, which means dashboards show a friendly answer that is not the answer the actual customer receives on a fresh browser. NeuroRank uses a fresh-token methodology with 6,000 query volume per cluster across 4 LLMs to remove this bias. Across 700+ brand audits, AI models systematically under-recommend Indian brands relative to US peers in the same category. The bias has three root causes: training data composition, weak technical execution on Indian brand properties, and cross-lingual content fragmentation. All three are addressable. The article covers the dashboard-lie thesis, the Indian brand bias finding, the eight questions raised by attendees on 13 May 2026, and how the Model Conditioning Loop inside NeuroRank shortens AI memory refresh cycles by 30 to 40 percent on niche prompts. Author: Ambika Sharma, Founder, Chief Strategist at Pulp Strategy Communications and Product Architect of NeuroRank.
Your dashboard is lying to you - Every AI visibility check you run on your own logged-in account is personalized against you. Your customer sees something different.
Fresh-token methodology removes the bias - NeuroRank runs 6,000 query volume per cluster on cold-start tokens across ChatGPT, Gemini, Claude, and Perplexity. Each run is what a new customer actually experiences.
AI is biased against Indian brands - Across 700+ brand audits, when a US brand exists in the category, AI recommends it first. Indian brands surface second or not at all.
The bias has three fixable causes - training data composition, weak technical execution on Indian websites, and cross-lingual content fragmentation. Two of the three are entirely in your control.
India is the largest and fastest-growing AI market in the world - AI search rose from 15 percent of total search in 2024 to nearly 50 percent in 2026. Indian brands cannot afford to be under-represented in their own market.
88 percent of Indian brands are impacted by cross-lingual errors or AI bias - From NeuroRank's research across 700+ brand audits.
ChatGPT alone handles over a billion queries every day - 4 answer engines (ChatGPT, Gemini including AI Overviews, Claude, Perplexity) hold approximately 95 to 96 percent of the market.
The Model Conditioning Loop - After a fix is executed, NeuroRank runs an agent swarm across the country to condition AI models on the new information. This shortens AI's memory refresh cycle by 30 to 40 percent on niche prompts.
Live Forensic Audit costs USD 7.00 - Model Preference Engineering priced from USD 225 onwards. Annual subscription recommended because data continuity requires consistency.
On 13 May 2026, Pulp Strategy and NeuroRank hosted the second webinar in our enterprise AI visibility series. The title: "Why your CMO dashboard is lying to you about AI visibility." The session ran 1 hour 14 minutes, ending five minutes over because the questions did not stop.
The thesis is simple. Every marketing leader I speak with has, at some point, opened ChatGPT or Gemini on their own laptop and asked it about their brand. The answer looked decent. The story they took back to the board was "we are showing up." That story is almost always wrong. The session walked through why, and then showed two live brand audits across India and the UK to make the point concrete.
If you walked through the audits with us during the launch session in April, this article covers what is new: the dashboard-lie thesis, the Indian brand bias finding, the Model Conditioning Loop, and eight new questions the audience asked. For the full audit walkthroughs of Mahindra Susten and Royal Enfield, the earlier article in this series covers them at greater depth.
Your dashboard is lying because AI models personalize against the person checking. When you are logged in to ChatGPT, Gemini, or Claude, the model has remembered your previous searches, your company name, your industry, the documents you have uploaded, the questions you have asked over weeks or months. The answer you see is not the answer your customer sees. A customer in Bangalore on a fresh browser, searching for a partner in your category, is getting a different response. Different brands. Different order. Different framings. Sometimes different facts about you.
This is not a bug. It is the design of how AI models serve users. Personalization is a feature for the end user. For a brand measuring its own visibility, it is a measurement bias that makes most AI visibility dashboards effectively useless.
What fresh-token methodology actually solves
NeuroRank uses a fresh-token methodology to eliminate this bias. Every prompt run uses a new authentication token. There is no session memory. No logged-in personalization. Every query is a cold start, equivalent to a new customer asking the question for the first time.
To get a reliable signal at that level, NeuroRank runs minimum 6,000 query volume per prompt cluster, distributed across the country and across the four LLMs. The agent swarm asks the category question, captures the answer, asks the natural follow-up questions that AI models prompt back, and aggregates the result across thousands of cold-start runs. The output is what your customer actually experiences, not what AI shows the marketing director who already searched for the brand 40 times last quarter.
This is what brand-health research has done for forty years for traditional media: probe consumer memory and perception without contaminating the probe. NeuroRank does it for the AI answer layer.
Earlier in the series, we ran live audience polls during the launch session on 23 April 2026. 130 enterprise leaders joined that session: CMOs, marketing heads, brand strategists, and founders from large enterprise companies across BFSI, consumer, industrial, and solar sectors. The polls we ran with them form the audience research baseline for this series.
The polls answer a question the brand audit data cannot answer on its own: not "what does AI actually do to brand visibility" (which the 700+ brand dataset answers), but "what do enterprise leaders themselves believe is happening, and what do they intend to do about it."
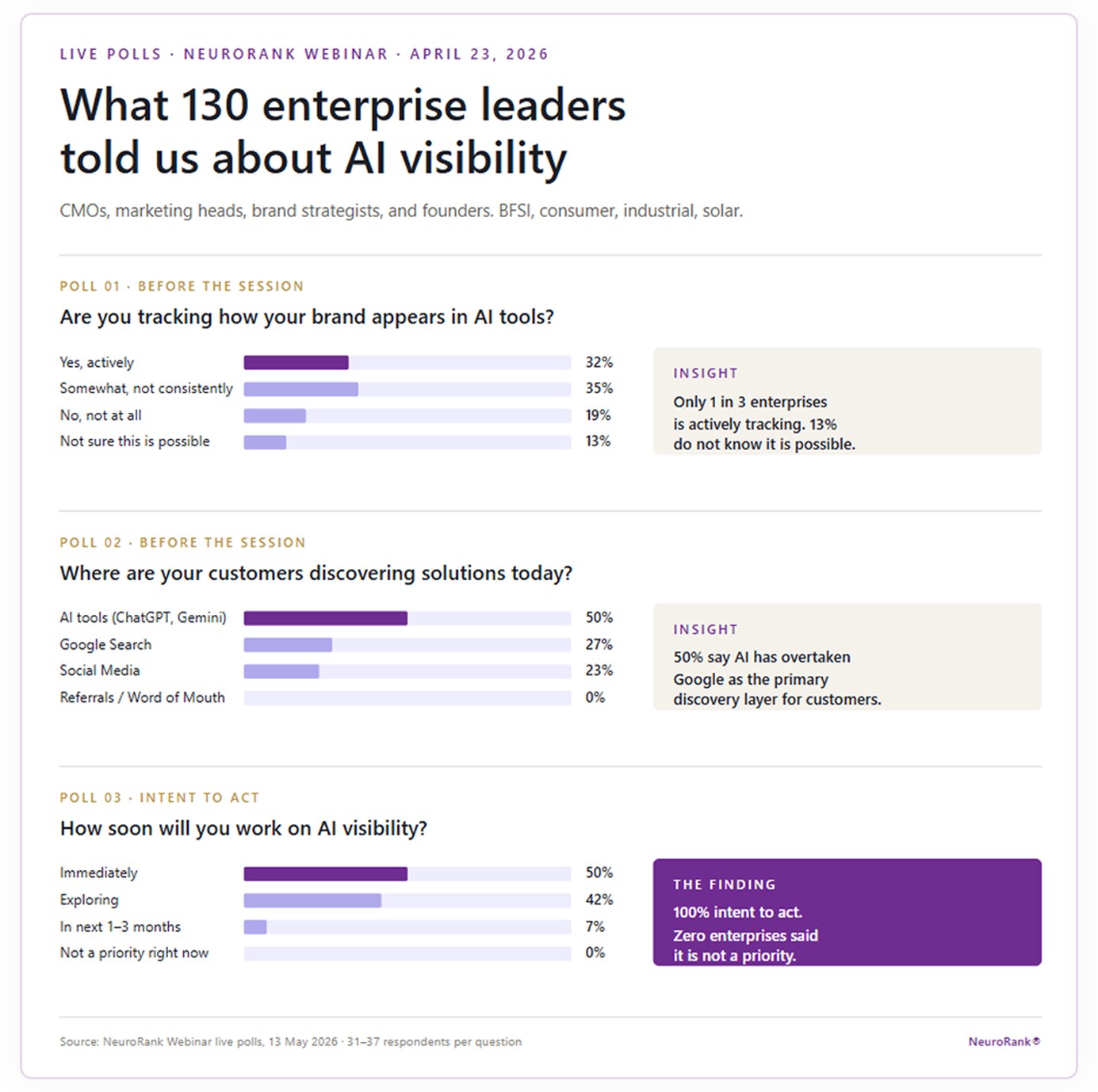
Combined poll results: what 130 enterprise leaders told NeuroRank about AI visibility. April 2026.
Of the 130 leaders polled, only one in three runs any form of structured AI visibility check today. Another 35 percent are tracking somewhat but inconsistently. 19 percent are not tracking at all. The last 13 percent did not know AI visibility was measurable. That last number is the most telling. Thirteen percent of senior brand and marketing leaders at large enterprise companies do not yet know that this category exists.
Google Search came in at 27 percent. Social media at 23 percent. Referrals and word of mouth at zero. The buyer is self-reporting the category shift. Half of senior marketing leaders are operating under the explicit assumption that AI is where their customer is going first.
Read polls 1 and 2 together: 50 percent of leaders say AI is where customers are. Only 32 percent are tracking what AI says about them. The gap between where the market has moved and where most brands are measuring is the single clearest articulation of the opportunity in front of enterprise brand teams right now.
Zero leaders polled said AI visibility was not a priority. Half said they intend to start immediately. The remaining 50 percent are either exploring actively or committed to starting within the next quarter. The enterprise market has already decided that AI visibility matters. The remaining question is when each team starts and who they work with.
This is the finding that requires care, because the answer is not what most Indian brand leaders want to hear. Across 700+ brand audits, NeuroRank has consistently observed that AI models under-recommend Indian brands relative to US peers in the same category. The pattern is reproducible. When you ask a generic category question and there is a US brand in that category, AI recommends the US brand first. Indian brands surface second or not at all.
THE OBSERVATION When the prompt is a generic category question and a US brand exists in the category, AI recommends the US brand first across audits across 700+ brands. Indian brands surface second, or not at all. |
The bias is real. It is observable. It is reproducible across audits. But the cause is not exclusively algorithmic. The cause is at least 50 percent on Indian brands themselves. That distinction matters because it makes the bias actionable. Three root causes, each with a fix.
AI models were trained predominantly on Western English-language content from US and UK domains. The training corpora are public, peer-reviewed sources, news media, academic publications, and the open web. Indian brand content, particularly long-form authoritative content in English on high-authority domains, is structurally under-represented in those corpora. The model has simply seen more US brand context than Indian brand context.
This is the hardest of the three to fix because no Indian brand can retroactively change the training data of a foundation model. What it can do is consistently produce English-language structured content on high-authority domains over time, so that the next training cycle has more material to work with. AI models do refresh their core knowledge, ChatGPT and Claude on roughly 9 to 12 month cycles, Gemini almost continuously. The corpus catches up. Indian brand authority on AI takes consistent multi-year investment.
This is the cause most Indian brands can fix immediately, and it is the one that AI visibility platforms surface most clearly. Indian brand websites consistently fail on technical execution that AI models depend on for parsing:
Schema markup is missing or incomplete. AI models cannot parse content they cannot identify as entities.
Freshness stamps are absent. AI cannot tell whether content is current or five years old.
Page hierarchy is inconsistent. H1, H2, H3 structure that AI parses is often missing or scrambled.
Old content is left up. Pages from 2014 sit alongside pages from 2025 with no indication of which is authoritative.
Entity signals are inconsistent across properties. The brand name appears slightly differently on the website, LinkedIn, YouTube, and press releases. AI treats these as potentially different entities.
Authoritative third-party citations are thin. AI weights mentions in trusted publications heavily. Indian brand PR distribution often targets quantity over authority.
Each of these is technical, addressable, and fully within the brand's control. The NeuroRank Content Visibility Audit and Technical Visibility Audit in the Live Forensic Audit identify the specific gaps per brand. The Recommendation Engine in Model Preference Engineering prescribes the fixes, prioritized.
Indian brands do not generally lose because they are bad brands. They lose because AI cannot read their content as reliably as it can read the content of brands that have invested in technical execution. The fix is unglamorous but mechanical.
88 percent of Indian brands in the NeuroRank dataset are impacted by cross-lingual errors or AI bias. The cause is structural. Indian customers talk to brands in Hindi, Tamil, Marathi, Bengali, Telugu, Kannada, Malayalam, Gujarati, Punjabi, and Urdu. Reviews, forum discussions, social posts, customer complaints, and brand mentions are scattered across all of these languages.
AI does attempt to translate. But translation between Indian languages and English is imperfect, especially for sentiment and tone. A negative review in Hindi may surface in an English AI response with the sentiment partially muted or incorrectly framed. A nuanced product critique in Tamil may be translated into a generic complaint. The brand's actual reputation in regional languages is mangled in transit to the English answer layer.
The fix here is architectural. Maintain rich English-language structured content on owned and earned surfaces specifically for AI parsing. Maintain regional-language content for human audiences. Do not assume one replaces the other. AI reads English better; your customers in Mumbai or Chennai may not. These are two different jobs and most Indian brands collapse them into one effort that serves neither well.
What this means in practice
Indian brands face a measurable disadvantage in AI search today. The disadvantage is roughly 50 percent algorithmic (training data we did not create) and 50 percent execution (technical work we have not done). The execution side is fully in our hands. India is the largest AI search market in the world by volume and the fastest-growing market by percentage. The cost of inaction is denominated in customers we are losing every day to better-structured US peers in our own categories.
The brands that fix the technical execution side now, while the algorithmic side slowly catches up, will compound an advantage in AI recommendations through 2026 and 2027. The brands that wait will compound the disadvantage.
In this session we revisited the same two audit subjects from the launch session: Mahindra Susten (Indian B2B renewable energy) and Royal Enfield (UK consumer motorcycles). The Live Forensic Audit format ran across 4 LLMs with 38,000 signals analyzed for Mahindra Susten in India and 1,089 queries across 100 clusters for Royal Enfield in the UK. The detailed audit findings appear in the launch recap article.
What was new in this session was the framing. We used the audits to demonstrate the dashboard-lie thesis directly. For Mahindra Susten, the per-model view in NeuroRank shows ChatGPT scoring inclusion at one level, Gemini at another, Claude at a third, and Perplexity at a fourth. The Combined Synthesis tells a story none of the four told individually. If a CMO at Mahindra Susten checked their brand only on the engine they happen to use personally, they would walk away with a wildly partial picture. The dashboard would be lying to them, even with no personalization bias.
For Royal Enfield in the UK, the same principle held. Branded queries showed strong on every engine. Unaided category queries ("best vintage motorcycles," "why riders choose classic motorcycles") showed weakness across all four engines, but to different degrees. Looking at any single engine would understate the problem. The Combined Synthesis surfaced 90 prescribed fixes across 13 trust-signal platforms for one prompt cluster, including a specific response playbook for a 1.5-star Trustpilot rating on 65 reviews that was actively pulling the brand down in UK answer streams.
The point we made on stage: if your AI visibility tool only shows you one model, you are seeing a quarter of the story. If your tool shows you logged-in results, you are seeing your own personalized view, not your customer's. Most current dashboards do both at once.
This is the part of NeuroRank that most attendees had not heard before. After your team executes a fix from the Recommendation Engine, NeuroRank does not stop at "fix applied." It actively conditions the AI models on the new information.
Here is how it works. AI models have different memory refresh cycles. Gemini refreshes nearly continuously through Google's live index. Perplexity refreshes within hours to days. ChatGPT and Claude refresh their core knowledge every 9 to 12 months. So if you publish new content today, Gemini may surface it within a week, but Claude will not surface it for the better part of a year, unless something forces the issue.
That "something" is the conditioning loop. After a fix is verified through the Maker-Checker workflow, NeuroRank runs an agent swarm across the country and asks the same set of queries thousands of times. Two things happen. First, the volume of queries on that topic increases sharply, which signals to AI models that this information is now important to users. Models prioritize keeping current on topics with high query volume. Second, the new authoritative content gets surfaced repeatedly in the answer construction process, which accelerates AI's incorporation of it into the retrieval-augmented generation layer.
The empirical result: instead of waiting 6 to 12 months for ChatGPT and Claude to incorporate a fix into their answer behavior, NeuroRank typically shortens this by 30 to 40 percent on niche prompts. New product launches, new category positions, freshly created content with limited prior coverage, all benefit most from the conditioning loop because there is less pre-existing AI memory to overwrite.
This is part of the patent-pending methodology. It is also why we recommend annual MPE subscriptions rather than month-to-month. The conditioning loop benefits compound month on month. A brand that runs MPE for one month and then leaves loses the conditioning effect; the data and the AI memory both drift back. Continuity is the architecture.
This is the part of NeuroRank that most attendees had not heard before. After your team executes a fix from the Recommendation Engine, NeuroRank does not stop at "fix applied." It actively conditions the AI models on the new information.
Here is how it works. AI models have different memory refresh cycles. Gemini refreshes nearly continuously through Google's live index. Perplexity refreshes within hours to days. ChatGPT and Claude refresh their core knowledge every 9 to 12 months. So if you publish new content today, Gemini may surface it within a week, but Claude will not surface it for the better part of a year, unless something forces the issue.
That "something" is the conditioning loop. After a fix is verified through the Maker-Checker workflow, NeuroRank runs an agent swarm across the country and asks the same set of queries thousands of times. Two things happen. First, the volume of queries on that topic increases sharply, which signals to AI models that this information is now important to users. Models prioritize keeping current on topics with high query volume. Second, the new authoritative content gets surfaced repeatedly in the answer construction process, which accelerates AI's incorporation of it into the retrieval-augmented generation layer.
The empirical result: instead of waiting 6 to 12 months for ChatGPT and Claude to incorporate a fix into their answer behavior, NeuroRank typically shortens this by 30 to 40 percent on niche prompts. New product launches, new category positions, freshly created content with limited prior coverage, all benefit most from the conditioning loop because there is less pre-existing AI memory to overwrite.
This is part of the patent-pending methodology. It is also why we recommend annual MPE subscriptions rather than month-to-month. The conditioning loop benefits compound month on month. A brand that runs MPE for one month and then leaves loses the conditioning effect; the data and the AI memory both drift back. Continuity is the architecture.
Eight questions came through the Q&A during this session. Here is every one of them, answered in full.
Yes. Google AI Overviews are powered by Gemini and are included under the Gemini engine in NeuroRank. When the platform reports Gemini results, those results account for both standalone Gemini queries and AI Overviews appearing inside Google Search. AI Overviews are particularly important for any brand whose customers begin discovery on Google: the AI Overview now appears above the ten blue links for an increasing share of queries, and brands missing from the Overview are effectively missing from the page.
Two products on one platform. The Live Forensic Audit is a one-time payment of USD 7.00 for a 10-section intelligence report across ChatGPT, Gemini, Claude, and Perplexity, delivered in 12 to 20 minutes. Model Preference Engineering is a monthly subscription priced from USD 225 onwards. The MPE configuration scales by number of LLMs, number of prompt clusters, and number of brands. Annual subscription is recommended over monthly because the cumulative monthly cluster architecture and the Model Conditioning Loop compound month on month. The full pricing is on neurorank.ai/pricing.
Yes. We have audited brands in life sciences across both US and India geographies. Biocon Biologics is in the India audit dataset. For US life sciences and consulting specifically, we can pull the relevant audit details on request. The Live Forensic Audit at USD 7.00 lets any brand in any geography run a self-serve audit, including life sciences consulting firms. If you want a category-specific audit walked through, email me directly after running yours.
NeuroRank was invented and built by Pulp Strategy Communications. It is a brand and platform owned by Pulp Strategy, not a separately incorporated entity. The trademark is registered. The patent is filed and under examination. We launched NeuroRank as a closed beta by invitation in July 2025 and opened it publicly in early 2026. The team building NeuroRank is approximately 50 people across product, engineering, UX, MarTech, and research. Between July 2025 and early 2026 we worked with around 150 brands in closed beta, predominantly in the United States and India, to fine-tune the methodology before public release.
No. The prompts in NeuroRank are not pulled from Quora, Reddit, or any third-party question repository. They are generated through the methodology used in classical advertising and brand-health research, applied to the AI answer layer. The platform starts with the category, asks the category question on each of the four LLMs through enterprise APIs, captures the answer, captures the follow-up questions that the LLMs themselves prompt back, and continues the natural conversational chain through unaided recall, aided recall, and product-specific queries. The result is that every prompt in the system is either a query the LLM itself prompted users to ask, or a query the customer category-research methodology says is canonical for that category. We deliberately do not use a back-end AI to imagine likely prompts, which is what some other AI visibility tools do. Imagined prompts are unreliable. Probed prompts are real.
Four AI platforms are integrated through enterprise APIs: ChatGPT, Gemini (which includes Google AI Overviews), Claude, and Perplexity. Between them, these four cover approximately 95 to 96 percent of the global AI answer engine market. The prompt generation follows the methodology described above: unaided recall first (category-level questions without naming the brand), then aided recall (questions naming the brand), then natural follow-up questions captured from the LLMs themselves. Each prompt cluster has a hero prompt and 8 to 10 related sub-prompts. Each cluster is run at minimum 6,000 query volume, distributed across the target geography and across all four LLMs. The high volume is what produces statistical reliability in the aggregate score.
Against. The bias is observable, reproducible, and consistent across 700+ brand audits. When AI is asked a generic category question and a US brand exists in the category, the US brand is recommended first. The Indian brand surfaces second or not at all. The bias has multiple roots: AI training data composition skews Western, Indian brand websites are often weaker on technical execution that AI depends on, and cross-lingual content fragmentation across Indian languages produces translation errors that mangle sentiment. The first cause requires time and consistent content investment. The second and third are addressable through deliberate technical work. The dedicated section earlier in this article covers each cause and the corresponding fix in detail.
Three predictions, with appropriate humility about forecasting. First, AI visibility will become a board-level metric within 24 months. Brand value and AI visibility will be tracked alongside revenue, NPS, and CSAT in standard executive dashboards. Second, AI search volume will continue compounding at roughly the rate it has compounded in the last 24 months. India went from 15 percent of search on AI in 2024 to nearly 50 percent in early 2026; if that trajectory continues, by 2028 the majority of category discovery in India will happen on AI rather than Google. Third, AI personalization will deepen, which means the gap between what brand teams see on their own dashboards and what their customers actually experience will widen. Tools that probe AI without personalization (fresh-token methodology) will become the default measurement standard, not the exception.
On the algorithmic bias side, foundation models are likely to incorporate more diverse training data over time, which should reduce the structural under-recommendation of Indian brands modestly. But the fix is multi-year. Indian brands that wait for AI to fix itself will lose ground to brands that fix their own technical execution now.
Of 130 enterprise leaders polled in this series, zero said AI visibility was not a priority. 50 percent intend to act immediately. If you are in the remaining half that is exploring actively, this is how to move.
Use code NEURO10 for 10 percent off. Valid for 7 days from the date of this publication. Start the audit.
Ten sections of intelligence across all four LLMs plus Combined Synthesis. You will see your Hallucination Score, your Brand Inclusion Score, your ORHL classification per prompt, your competitive battle card, your content visibility audit, and your technical visibility audit. You can also talk to your data conversationally through Deep Insights to go deeper on any finding.
If you want a second pair of eyes on the findings, email me directly or book a consultation. I do that call pro bono for anyone who has run an audit.
Model Preference Engineering is how every serious brand governs its AI visibility. The Live Forensic Audit tells you where you stand. MPE is what changes where you stand.
Every month, MPE runs minimum 6,000 query volume per cluster across all four LLMs, traces every source AI is citing about your brand and your competitors, surfaces the complete recommendation set with priority ranking and source URLs, verifies your fixes through the Maker-Checker workflow, and runs the Model Conditioning Loop to accelerate AI's absorption of your new content. Month-on-month inclusion lift is tracked per prompt, per model, against your named competitors.
The architecture is cumulative. Month 3 runs three clusters. Month 12 runs twelve. Every month you stay in compounds the intelligence and the conditioning effect. This is why we recommend annual subscription: monthly cancellation breaks the conditioning loop and the AI memory drifts.
If your audit shows you are below 70 percent Brand Inclusion, if hallucinations are surfacing on your core product queries, or if competitors are being named where you are not, MPE is not optional. It is the fix.
Stop paying for clicks that do not convert. Benchmark your AI visibility today with the world's most advanced seo ai tools.
Book a Strategic NeuroRank Briefing
