

BlogJune 4, 2026
GEO Strategy After Google’s AI Mode: The Click Contract Is Dead

Ambika SharmaFounder at Pulp Strategy Communications and NeuroRank.

Ambika Sharma
Ambika Sharma is the Founder & Chief Strategist of Pulp Strategy, a multi-award-winning business transformation and digital agency, and Prod... Read more
AI search misrepresents Indian pharma. Across ChatGPT, Gemini, Claude, and Perplexity, the structural failure is consistent: regulated brands are misclassified, conflated, omitted, or hallucinated around. This is not a story about specific companies. It is a story about a category that has not built the structured evidence AI engines need to retrieve it accurately.
NeuroRank® audited a category-leading brand from each of the five operating-model archetypes that define Indian pharma: specialty drugs and generics, biosimilars and biologics, branded pharma combined with consumer health, discovery and development services, and contract development and manufacturing at scale. Across all five archetypes and four engines, the same structural failure recurs. pulp strategy
Healthcare AI visibility is no longer a marketing concern. It is a clinical, compliance, and capital-markets event the brand did not author and cannot see.
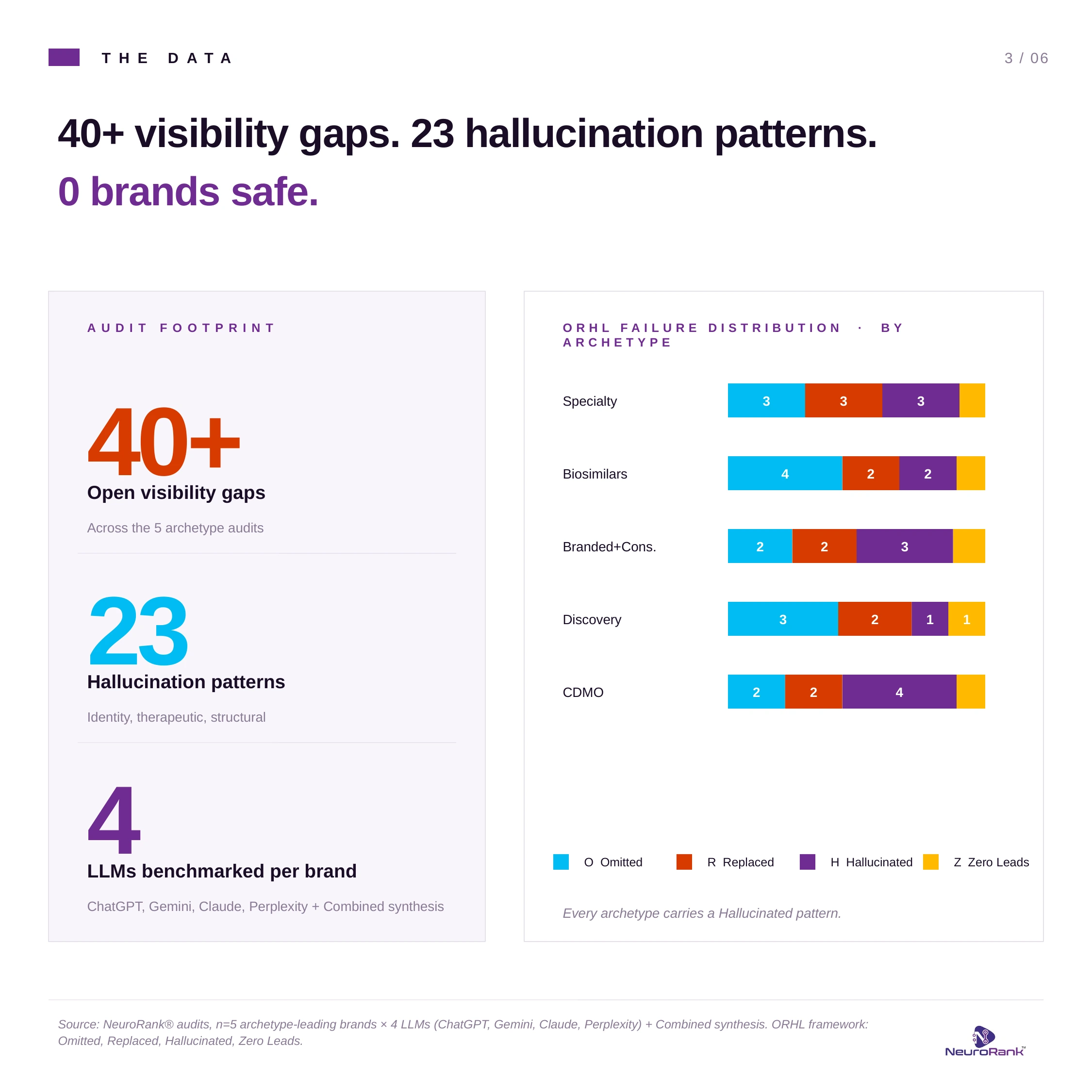
AI search is now the discovery layer for medical, investor, regulator, and procurement decisions in Indian pharma, and the category leaders are not safe inside it. NeuroRank® audits across ChatGPT, Gemini, Claude, Perplexity, and the Combined synthesis / NeuroRank Benchmark covering five operating-model archetypes in Indian pharma surfaced more than 40 open visibility gaps and at least 23 distinct hallucination patterns. The shared root cause is structural. Schema markup on product and service pages is missing or sparse. Parent-subsidiary architecture is illegible to language models. Trust signals such as therapeutic-area authority, biosimilar pioneer credentials, EU-GMP certification, FDA-approved manufacturing, and capital-markets credentials sit inside PDFs, and corporate press releases that engines parse poorly. The consequence is direct. Misrepresentation in regulated categories creates compliance exposure, depresses prescriber confidence, distorts investor narrative, and shrinks the consideration set at the moment of recommendation.

Generative Engine Optimization (GEO) is the practice of structuring a brand's verifiable, machine-readable evidence so language models retrieve, cite, and reproduce it accurately. For pharma, GEO governs how AI engines describe therapeutic areas, regulatory standing, biosimilar credentials, and parent-subsidiary structure to prescribers, patients, and investors.
Specialty-drugs archetype: a category leader is described as primarily OTC. Specialty depth is absent. Cipla and Dr. Reddy's are recalled as innovation leaders in the space.
Biosimilars archetype: parent and listed-subsidiary biologics entities are conflated, distorting governance, valuation, and regulatory accountability for separately listed entities.
Branded-pharma-plus-consumer-health archetype: three legally separate group entities are blurred into one brand, and consumer health sub-brands are misattributed to the parent.
Discovery and development services archetype: a leading CDMO is overshadowed by Syngene International and by its own parent in CDMO and drug discovery answers.
Contract manufacturing archetype: an India-leading CDMO is confused with a similarly named but unrelated pharmaceutical company, with direct supplier-shortlist consequences.
Across all five archetypes, schema markup on product or service pages is rated absent, sparse, or weak, blocking AI ingestion of approvals, indications, and entity structure.
Inclusion is high in surface-level prompts. Discriminating prompts about therapeutic depth, parent-subsidiary structure, and regulatory standing are where the category loses.
In a regulated category, AI hallucination is not a marketing error. It is a clinical, compliance, and capital market event.
Ambika Sharma, Founder, Chief Strategist at Pulp Strategy Communications and Product Architect of NeuroRank®

Most Indian pharma companies were built for prescriber relationships, regulator submissions, and global B2B contract manufacturing. They were not built to be parsed by language models. Their proof sits in places AI engines retrieve poorly. Annual reports as PDFs. CDSCO approval lists in scanned documents. Therapeutic-area authority inside conference keynotes that never make it to a structured page. WHO-GMP and EU-GMP certificates as image files. Pioneer claims and FDA-cleared facility claims in press releases the engine cannot read.
AI search engines do not read this evidence. They read the open web, structured data, Wikipedia, news aggregators, regulatory databases, and publisher metadata. Where the brand has not laid down structured markers, the engine fills the gap with what is easiest to retrieve. That is almost never the most accurate description. It is the most quotable one.
Three shifts make this urgent. Prescriber, patient, regulator, and investor research is moving to generative engines as a first stop. Hallucinations in pharma do not stay inside marketing: a wrong therapeutic claim is a Schedule H concern, a misstated approval is a regulatory disclosure issue, a confused parent-subsidiary description is a securities communication problem, and a confused contract manufacturer identity is a supply-chain trust event. The CMO inherits the surface. The chief medical officer, general counsel, CFO, and head of investor relations inherit the consequence. India's pharma sector spans five distinct operating models inside one category: specialty and generic drugs, biosimilars, branded consumer health, discovery and development services, and contract manufacturing and packaging. AI engines have not learned to tell them apart.
People also ask: how is healthcare AI visibility different from healthcare SEO? Healthcare SEO ranks pages on Google for clinical and commercial terms. Healthcare AI visibility governs how language models retrieve, summarize, and quote those pages, often without sending the user to the website at all. The first protects clicks. The second protects the brand narrative.
Across the five audits, four failure patterns recurred across ChatGPT, Gemini, Claude, and Perplexity. They map to the four classes of AI failure NeuroRank tracks under the ORHL framework. They are not theoretical. Every example below is from the audit set referenced in this article.
The brand is omitted entirely. Sun Pharma is missing from AI-generated answers on dermatology innovation in India, despite leading the country in topical dermatology revenue. Biocon is underrepresented in answers on biosimilar approvals, despite being the company that brought biosimilar insulin Glargine to India. Aurigene is absent or minimal in CDMO comparisons where Syngene dominates.
The brand is replaced by a competitor. When AI engines are asked who leads cardiology innovation in Indian pharma, Cipla and Dr. Reddy's are returned by name. Sun Pharma's cardiology portfolio sits as background. In contract manufacturing, Akums is overshadowed in AI-generated supplier directories by Syngene, Piramal Pharma Solutions, and Divi's Laboratories, even though Akums operates 12 formulation facilities and 2 API plants and serves more than 60 export markets. In drug discovery, Aurigene is replaced by its own parent. AI engines repeatedly attribute Aurigene's discovery work to Dr. Reddy's directly.
The brand is hallucinated. Sun Pharma is described as primarily OTC. Biocon Limited and Biocon Biologics are treated as one entity. Zydus Healthcare, Zydus Lifesciences, and Zydus Wellness are blurred. AI claims Akums manufactures specific drugs that are under patent protection, when Akums is a contract manufacturer. AI claims Akums was acquired by a foreign company. There is no public record of such an acquisition. Most consequentially, AI confuses Akums with Akumentis Healthcare, a separate company with a different business.
The brand has zero leads. The answer is technically correct but commercially useless. Sun Pharma is named in a list of generic manufacturers without therapeutic specialisation. Biocon is named in a list of Indian biotech companies without acknowledging it is the country's pioneer in biosimilars. Aurigene is named in a list of CROs without acknowledging it has contributed to two FDA novel drug approvals. The brand surfaces, but with nothing in the answer that would drive prescriber preference, investor confidence, partnership inbound, or supplier shortlist.

ORHL is the diagnostic backbone of every NeuroRank audit. The acronym stands for Omitted, Replaced, Hallucinated, and Zero Leads. Every failure surfaced across ChatGPT, Gemini, Claude, and Perplexity is classified into one of these four categories, with named brand evidence and a prescribed structural fix. The four classes are not abstract. They map directly to the failures pharma brands experience in prescriber, investor, and supplier conversations.
Class | Code | What it looks like in pharma |
Omitted | O | Brand absent from category answers it should lead. Sun Pharma missing from dermatology innovation; Biocon missing from biosimilar approvals; Aurigene minimal in CDMO comparisons. |
Replaced | R | Competitor named in your place. Dr. Reddy's recalled as innovation leader; Cipla as cardiology authority; Syngene replacing Aurigene in CDMO answers; Piramal replacing Akums in manufacturing directories. |
Hallucinated | H | Confident, articulate misinformation. Sun Pharma as OTC-first; Biocon Limited and Biologics conflated; Zydus three-entity blur; Akums confused with Akumentis Healthcare; Aurigene work attributed to Dr. Reddy's. |
Zero Leads | Z | Brand mentioned without commercial value. Named on a generics list with no therapeutic depth, no innovation cue, no buying trigger, no investor narrative. |
Deconstruct: dismantle the LLM's internal representation of your brand. Diagnose: classify visibility gaps across ChatGPT, Claude, Gemini, and Perplexity. Prescribe: issue the specific content, CMS, and other actions required to fix them. Condition: run the Model Conditioning Loop across owned, earned, and third-party surfaces. Track: measure month-on-month lift as the models recalibrate.
The audited category leader in this archetype is one of India's largest pharmaceutical companies, recognized globally as a top specialty generic player and a domestic leader in dermatology innovation. AI engines describe the brand as primarily an over-the-counter business. Its OTC range is in fact a fraction of revenue. The audit logged 53 source links across eight visibility surfaces and 10 open gaps. Five were tagged critical. For purposes of grounding the analysis, the audited brand is Sun Pharma.
The most consequential gap is structured data. Product pages lack comprehensive schema markup, so therapeutic indications, dosage forms, and approval status are illegible to language models. The second is leadership thought-content. The CEO and chief scientific officer are absent from the 'who leads' answers where Cipla and Dr. Reddy's now appear by default. The third is content velocity. Therapeutic-area blog content is light, AI-citable case studies are missing, and there is no verified official YouTube channel surfacing product explainers in a format engines can transcribe and quote.
Three hallucination patterns recurred. Parent-product structure was confused. Historic FDA warning-letter coverage surfaced without the corrective context that has been public for years. The OTC misclassification dominated retail-investor and patient prompts. None of these are marketing inconveniences. Each carries a distinct exposure: prescriber doubt, regulator perception, and retail-investor narrative drift.
Atomic answer: in the specialty-drugs archetype, the category leader is hallucinated as primarily over-the-counter, omitted from dermatology and cardiology innovation answers, and replaced by Cipla and Dr. Reddy's in leadership and innovation queries. The structural cause is missing product schema, sparse executive content, and minimal AI-citable proof of therapeutic depth. The cause is not brand-specific. It is category-specific.
AI engines treat the listed parent and the listed biologics subsidiary in this archetype as the same entity. They are not. The parent is a holding company; the biosimilars subsidiary is a separately listed entity with distinct governance, ESG profile, and capital structure. Conflating them distorts every investor-facing prompt about valuation, every governance-facing prompt about accountability, and every clinical prompt about which entity carries which approval. The audit logged 40 source links across eight visibility surfaces and nine open gaps. Five were tagged critical. For grounding, the audited brand is Biocon.
The biosimilar pioneer credential is the clearest example of category leadership turning into category invisibility. The brand brought biosimilar insulin Glargine to India and operates a global biosimilars portfolio across monoclonal antibodies, insulins, and conjugated recombinant proteins. AI answers on biosimilars in India routinely omit the brand as the lead voice. The prompts surface Dr. Reddy's, Cipla, and Intas with stronger structured proof in AI-readable form. The brand's evidence sits inside campaign pages, awards-and-recognition pages, and investor announcements that are not parsed as authoritative answer sources.
Two hallucination patterns recurred across ChatGPT, Gemini, and Claude. The parent and biosimilars-subsidiary conflation appeared in nearly every entity-level prompt. Market-share claims appeared without credible source attribution, sometimes overstated, sometimes misattributed to the wrong subsidiary. The brand is recognized as a credible biosimilar developer in regulatory documents and global partnerships. AI search has not absorbed that recognition into the answers it returns to customers, partners, and analysts.
Atomic answer: in the biosimilars archetype, the category leader is hallucinated as a single undifferentiated entity, omitted from biosimilar pioneer answers despite leading insulin Glargine in India, and replaced by Dr. Reddy's and Intas in contract-manufacturing queries. The structural cause is absent product schema, parent-subsidiary ambiguity in machine-readable form, and missing citation-ready press evidence. Every Indian biosimilars brand faces the same illegibility problem.
AI engines blur three legally separate group entities into a single ambiguous brand. The listed parent is a pharmaceutical group founded in 1988. A consumer-facing pharmaceutical brand sits as a subsidiary, focused on prescription medications, OTC, nutraceuticals, biologics, and vaccines. A separately listed consumer goods company within the same group holds well-known FMCG sub-brands. Three governance structures. Three balance sheets. One AI answer. For grounding, the audited brand is Zydus Healthcare under the Zydus Lifesciences group.
The Combined synthesis flagged the most damaging hallucination directly. Some engines describe the consumer-facing pharmaceutical brand as 'primarily involved in direct patient care' rather than pharmaceutical manufacturing and distribution. The brand does not run hospitals. It manufactures and distributes drugs. Misclassifying a listed pharma group's subsidiary as a hospital chain has direct implications for analyst coverage, supplier shortlists, and regulatory perception.
Other hallucinations followed the same pattern. Inaccurate claims about the brand's product range. Overstatement of market leadership compared with category leaders. Confusion between the standalone brand and consumer brands owned by the separately listed sister company. Schema markup on product pages is rated weak. Search visibility for branded products is light. Local SEO for pharmacy partnerships is missing entirely.
Atomic answer: in the branded-pharma-plus-consumer-health archetype, the category leader is hallucinated as a single undifferentiated entity that includes a hospital chain it does not run, omitted from comparative innovation answers in favor of larger peers, and replaced in OTC and nutraceutical answers by louder consumer brands. The structural cause is absent entity-level schema, missing parent-subsidiary disambiguation, and weak product-page structured data.
The audited category-representative brand in this archetype is the CDMO and discovery services subsidiary of a globally recognized Indian pharmaceutical company. AI engines do not see it as separate. In CDMO comparisons, Syngene International dominates and the audited brand is mentioned in context, never as the answer. In drug discovery answers, the engine attributes the brand's work to its parent. The Combined synthesis named the failure cleanly: low standalone brand recall in LLM responses for CDMO queries, overshadowed by parent mentions. For grounding, the audited brand is Aurigene Pharmaceutical Services, a subsidiary of Dr. Reddy's Laboratories.
The structural cost is precise. The audited brand operates across the full drug development lifecycle from early-stage discovery through clinical development to commercial-scale manufacturing, with facilities in India, the United Kingdom, and Mexico. It has contributed to two FDA novel drug approvals. It serves long-term partnerships with two of the top five global pharmaceutical companies. None of this surfaces in AI answers. Engines default to Syngene, Biocon, or the parent.
Three patterns repeat. The brand is absent from 'integrated drug development services in India' answers where competitors have a stronger digital footprint. It is minimal or absent in 'best CRDMOs in India' lists. Executive visibility is low. There is no LinkedIn or Twitter brand handle of consequence, no thought-leadership program, and no press cycle dedicated to the brand's standalone wins. The schema on service pages is sparse.
Atomic answer: in the discovery and development services archetype, the category-representative brand is omitted from CDMO and CRDMO answers, replaced by Syngene International and its own parent, and treated in zero-leads form when included. The structural cause is absent standalone case studies, missing service-page schema, and no executive thought-leadership program separating the brand from the parent identity.
The audited category leader in this archetype is India's largest contract development and manufacturing organization. The brand operates 12 formulation facilities and two API plants, holds EU-GMP, WHO-GMP, ISO 9001, 14001, 45001, and 50001 certifications, exports to more than 60 countries, signed a 1,760 crore European supply contract, took investment from Quadria Capital, and listed on Indian stock exchanges in 2024. AI engines are not parsing any of that as authoritative. The Combined synthesis flagged the most consequential hallucination first: confusion between the audited brand and a separately named pharmaceutical company. For grounding, the audited brand is Akums Drugs and Pharmaceuticals; the brand it is confused with is Akumentis Healthcare.
Akumentis Healthcare is a different company with a different business. The fact that engines confuse the two has direct supplier-shortlist consequences. A multinational asking AI for a CDMO partner is being given the wrong company. A buy-side analyst tracking a recent IPO is reading information about a brand the analyst was not researching.
Other hallucinations followed. AI claims the brand manufactures specific drugs under patent protection, when the brand is a contract manufacturer that produces under client formulations. AI claims a foreign acquisition, with no public record. AI misstates headquarters location and international partnerships. The MD, recognized in industry awards, is absent from leadership answers about Indian pharma. The brand sits in zero-leads form across most prompts.
Atomic answer: in the contract manufacturing archetype, the category leader is hallucinated through identity confusion with a similarly named but unrelated pharmaceutical company, omitted from supplier-shortlist answers despite scale and EU-GMP credentials, and replaced in CDMO directories by Syngene, Piramal, and Divi's. The structural cause is missing entity-level disambiguation, sparse schema on capability pages, and minimal AI-citable proof of recent capital-markets events.

Prescriber preference is shifting at the discovery layer. Doctors and chemists run AI prompts to compare therapy options and manufacturers between visits. When the category leader is described as primarily OTC, or when a biosimilar pioneer is treated as undifferentiated, the brand loses the consideration before the medical representative arrives.
Investor narrative is being rewritten without the brand's consent. Buy-side analysts use generative engines for first-pass research on Indian pharma. A parent-subsidiary conflation distorts the cap-table conversation. A misclassified specialty-drug narrative depresses the premium the company has spent two decades building. An identity collision with a similarly named but unrelated company sends the wrong information to anyone tracking a recent IPO.
Procurement is being misdirected. CDMO supplier shortlists generated by AI engines are placing scaled Indian CDMOs behind smaller-footprint peers. Multinational procurement teams running first-pass screens through ChatGPT or Gemini are receiving inaccurate supplier information. The conversion lift competitors gain is a contract event, not a marketing event.
Regulatory and patient exposure is direct. AI engines repeating outdated FDA warning context without the corrective record creates a discovery-layer story that is technically wrong and reputationally costly. Schedule H drugs misframed as OTC create patient-safety exposure. A pharma brand that cannot govern how AI describes its products is not failing at SEO. It is failing at category responsibility.
Pharma brands that govern AI visibility recover prescriber consideration, investor narrative, and supplier-shortlist position before competitors take the seat. The mechanism is structured evidence: schema, regulator-cited approvals, and entity disambiguation engines retrieve as authoritative. Pew Research found AI Overview clicks run roughly half the rate of conventional results.
Most AI visibility tools monitor mentions. NeuroRank® diagnoses why the misrepresentation is happening, prescribes the structured fixes, conditions the engines, and tracks inclusion growth month on month.
Monitoring tools tell pharma brands what AI is saying. That is the first 10 percent of the work. The other 90 percent is figuring out why the engine is saying it, what evidence is missing, what schema the brand has failed to publish, what regulator-grade signals the model has failed to ingest, and how to condition future answers without hallucinating in the other direction.
NeuroRank® was built forthat 90 percent. The platform combines a Live Forensic Audit, which surfaces hallucinations, omissions, replacements, and zero-lead failures across ChatGPT, Gemini, Claude, and Perplexity, with Model Preference Engineering, the monthly program that closes the gaps through a Model Conditioning Loop. Combined synthesis across the four engines produces the NeuroRank Benchmark, which is then tracked for inclusion growth and narrative health, month on month. The discipline is governance, not measurement.
For Indian pharma specifically, the difference is structural. A monitoring tool will report that ChatGPT confused Akums with Akumentis Healthcare. It will not tell the brand that the underlying cause is missing entity-disambiguation schema, sparse press evidence linking the corporate identity to the IPO, and absent thought-leadership content from the MD. NeuroRank traces every hallucination back to the structured-evidence failure that produced it, prescribes the fix at the schema, content, or PR layer, and reruns the prompt cluster the following month to verify the engine has absorbed the correction. Monitoring shows the symptom. Governance closes the loop.
The table summarizes all five archetypes on a single line. Each row is one archetype, the audited illustrative brand, the dominant ORHL pattern, and the most material hallucination. Three observations recur across the rows. Every archetype shows a Hallucinated pattern. The most damaging hallucinations are identity claims, not therapeutic claims. The structural cause is the same: missing or weak machine-readable evidence.
Archetype | Illustrative brand | Primary ORHL pattern | Most material hallucination |
Specialty drugs and generics | Sun Pharma | Hallucinated and Omitted | Described as primarily OTC; specialty-drug authority absent in AI answers. |
Biosimilars and biologics | Biocon | Hallucinated and Replaced | Parent and listed biologics subsidiary conflated as one entity. |
Branded pharma plus consumer health | Zydus Healthcare | Hallucinated and Replaced | Group entities blurred; consumer-pharma brand mistaken for a hospital chain. |
Discovery and development services | Aurigene | Omitted and Replaced | Standalone work attributed to parent; Syngene returned as the answer. |
Contract manufacturing CDMO | Akums | Hallucinated and Zero Leads | Confused with a similarly named but unrelated company; manufacturing scale absent from answers. |
Source: NeuroRank® audits across ChatGPT, Gemini, Claude, Perplexity, and the Combined synthesis / NeuroRank Benchmark. The hallucination patterns described are observations of LLM outputs at the time of analysis. Model behavior shifts as retrieval and training data refresh. See full disclaimer at the end of this article.
The five archetypes are not the exception. They are the indicator. The competitive analysis inside the audits names the brands currently winning AI inclusion share inside the same answer surfaces.
Dr. Reddy's Laboratories shows the strongest AI footprint among Indian pharma peers. The combination of high innovation perception, strong CEO and leadership content, and consistent prompt inclusion across innovation, R&D, and trust prompts is the template AI engines have absorbed. Dr. Reddy's also benefits from a structural advantage: it owns Aurigene, and the engines credit Dr. Reddy's directly for Aurigene's CDMO and discovery work.
Cipla holds tier-1 standing in cardiology and respiratory recall, particularly in India-specific prompts. Lupin holds steady in trust and recall but is rated medium across innovation and digital signals. Aurobindo Pharma sits at the lower end on innovation, recall, leadership, and digital engagement, named in lists rather than answers.
In the CDMO and discovery services category, Syngene International dominates. It is the brand engines reach for when asked about contract research, drug discovery, or integrated services in India. Piramal Pharma Solutions and Divi's Laboratories take inclusion share in API and contract manufacturing answers where Akums could lead with its EU-GMP credentials and 60-plus export markets.
In biosimilars, Intas Pharmaceuticals and Wockhardt show up in answers Biocon should own. Mankind Pharma surfaces in branded generics answers Zydus should be leading. Across all five competitive sets, the pattern is consistent: the brands winning AI inclusion are the brands that have laid down structured machine-readable proof. The brands losing are the brands that have not.
People also ask: which Indian pharma brand has the best AI visibility today? Across the audits referenced in this article, Dr. Reddy's Laboratories shows the strongest AI footprint, driven by leadership content, structured product evidence, and consistent inclusion across innovation, R&D, and trust prompts. Syngene International leads in CDMO and discovery services answers.
Three regional dynamics make Indian pharma a harder GEO problem than its US or European counterpart, and a harder governance problem for the brand.
First, the regulatory layer in India is fragmented across CDSCO at the center, state drug controllers, and a Schedule-classified drug system that AI engines do not parse natively. Without structured machine-readable markers indicating Schedule H, Schedule H1, and Schedule X status by product, language models default to whatever description is loudest on the open web. That description is rarely the regulator's. CDMOs face a related challenge. Without structured certifications data, AI engines cannot reliably distinguish between WHO-GMP, EU-GMP, and US-FDA-cleared facilities, and the supplier shortlist suffers.
Second, biosimilars carry a regulatory designation that AI search has not learned to handle in the Indian context. CDSCO's biosimilar approval pathway has different evidentiary thresholds than the EMA or FDA pathways. AI engines that confuse biosimilars with generics, or treat a CDSCO approval as equivalent to an EMA prequalification, distort the global narrative for Indian pharma exporters. This is the structural reason Biocon's pioneer credential disappears in AI answers despite being verifiable in regulator records.
Third, the linguistic layer matters. Indian patients and prescribers query AI engines in English, Hindi, and a hybrid that uses English clinical terms inside Hindi sentence structure. Brand names transliterate inconsistently. Volini, Pantocid, Susten, Lipaglyn, Liva, and dozens of category-leading molecule and brand names show drift across language settings. A brand that has not published Hindi-English structured product information cedes the consumer-language layer to whichever competitor has.
People also ask: do Indian pharma brands need separate Hindi-English schema markup? Yes. AI engines retrieve product information differently across language settings, and brands that publish only English-language schema markup lose visibility in Hindi-English hybrid prompts that dominate retail patient queries.
This article does not cover individual drug-level pharmacovigilance reporting, country-by-country regulatory submissions, or pricing-policy interpretations. It does not certify any product or corporate claim made by any audited or referenced brand. It does not predict how AI engines will retrieve any of these brands in subsequent audit cycles. It is a category analysis grounded in NeuroRank® audits of five operating-model archetypes in Indian pharma. Brand-level fixes are scoped through a Live Forensic Audit and addressed inside Model Preference Engineering.
Run a Live Forensic Audit on your brand and the two competitors AI engines are most likely to surface in your place. Read every hallucination as if it had been written by your CMO, your chief medical officer, and your CFO together. The cost of finding out is USD 7. The cost of not knowing is paid downstream, in prescriber doubt, investor narrative drift, supplier-shortlist exclusion, and regulatory exposure. The asymmetry is the point.
When AI tells your brand's story, is it telling the truth?
Stop paying for clicks that do not convert. Benchmark your AI visibility today with the world's most advanced seo ai tools.
Book a Strategic NeuroRank Briefing
