


BlogJune 4, 2026
GEO Strategy After Google’s AI Mode: The Click Contract Is Dead

Ambika SharmaFounder at Pulp Strategy Communications and NeuroRank.
Ambika Sharma
Ambika Sharma is the Founder & Chief Strategist of Pulp Strategy, a multi-award-winning business transformation and digital agency, and Prod... Read more
By Ambika Sharma, Founder, Chief Strategist at Pulp Strategy Communications and Product Architect of NeuroRank
Published: April 23, 2026 | Last updated: April 23, 2026 | 18 min readTopic: AI Visibility, LLMO, Brand Intelligence | Originally presented at the Pulp Strategy + NeuroRank webinar series, "AI Invisibility is costing your brand more than you think. It's time to fix it!"
Enterprise brand visibility has structurally moved from Google to AI answer engines (ChatGPT, Gemini, Claude, Perplexity), yet only 32 percent of enterprise leaders actively track how AI represents their brand. NeuroRank's research of 700+ brands across 65 industries shows 68 percent are missing from AI shortlists in their own category, 52 percent have active hallucinations, 88 percent are impacted by cross-lingual errors, and 90 percent in consumer categories show negative sentiment bias in AI summaries. The NeuroRank platform (patent-pending) diagnoses, prescribes, conditions, and tracks AI visibility using the proprietary ORHL failure taxonomy and a fresh-token methodology. A Live Forensic Audit costs USD 7.00. Model Preference Engineering is priced from USD 225 onwards. The practice is called LLMO: Large Language Model Optimization. Author: Ambika Sharma, Founder, Chief Strategist at Pulp Strategy Communications and Product Architect of NeuroRank.
Search has structurally changed. 25 to 30 percent of total search has moved to AI models. ChatGPT alone handles more than a billion queries.
Live poll of 130 enterprise attendees: only 32% are actively tracking AI visibility. 50% believe AI has already overtaken Google as primary discovery. 100% intend to act on AI visibility; 50% immediately.
Four AI engines now hold the decision layer: ChatGPT, Gemini (including Google AI Overviews), Claude, and Perplexity. Between them, they cover about 99 percent of the addressable market.
From 700+ brand audits: 68 percent are missing from AI shortlists in their own category. 52 percent have active hallucinations. 88 percent are impacted by cross-lingual errors. 90 percent in consumer categories show negative sentiment bias.
ORHL is the proprietary failure taxonomy: every AI visibility failure fits one of four categories: Omitted, Replaced, Hallucinated, or Zero Leads. This is patent-pending.
The Brand Inclusion Score is the core visibility metric. Formula: (prompt responses mentioning your brand ÷ total prompt responses executed) × 100. Computed per prompt, per cluster, per model, and in aggregate.
Two live audits on stage: Mahindra Susten (B2B renewable energy, India) and Royal Enfield (consumer motorcycles, UK market). Both surfaced actionable findings within minutes.
The Recommendation Engine produces extreme detail. One prompt on Royal Enfield surfaced 90 recommended fixes and 13 trust-signal platforms where the brand was missing. Even a 1.5-star Trustpilot rating was identified with a specific response recommendation.
200+ prompt clusters across 4 LLMs means roughly 2,000 customer prompts tracked, cited, and diagnosed per brand, per cycle, at scale.
Pricing is USD 7 for a Live Forensic Audit (one-time, 12 to 20 minutes). Model Preference Engineering is priced from USD 225 onwards.
Code NEURO10 is valid for 7 days from April 23, 2026, for 10 percent off a Live Forensic Audit.
On April 23, 2026, Pulp Strategy and NeuroRank hosted a webinar titled "AI Invisibility is costing your brand more than you think. It's time to fix it!" 130 enterprise leaders joined the live session: CMOs, marketing heads, brand strategists, and founders from large enterprise companies across BFSI, consumer, industrial, and solar sectors. The one-hour session ran to 1 hour 44 minutes because attendees kept asking questions, and I kept wanting to answer them properly rather than wave at them and move on.
This post is what I would have covered if we had another hour. It is structured around the ideas that landed hardest on stage, the two live brand audits walked through on the session, the four live polls that captured what enterprise leaders actually think about AI visibility, two substantive exchanges with attendees (a senior professional from a leading global newswire's managed services division and a brand leader from a leading Indian solar enterprise), and the 17 questions from the Q&A. If you were in the room, this is the deeper version. If you were not, this is the session condensed into something you can read in 18 minutes.
Search has structurally changed. 25 to 30 percent of total search has moved to AI models. ChatGPT alone handles more than a billion queries. There are four large AI models and a handful of smaller ones. Between ChatGPT, Gemini (which includes Google's AI Overviews), Claude, and Perplexity, roughly 99 percent of the market is covered.
The old pattern was: customer searches, sees ten blue links, clicks through, lands on your site, decides. The new pattern is: customer asks a question, an AI model fans the query out across the internet, synthesizes an answer, and recommends two or three brands by name. There is no list of ten. There is one paragraph. Your brand is either in that paragraph, or it is not.
BrightEdge has reported a referral traffic drop of up to 79 percent for brands that previously held Google's number one position, once AI summaries enter the frame. Pew Research found that only 8 percent of users click citation links when AI summaries appear, versus 15 percent without them. Gartner says 70 percent of consumers already trust AI-generated answers, and 79 percent are using or planning to use AI-enhanced search within the year.This is already showing up in paid search performance. Google Ads rolled out query fan-out for ad delivery in February 2026, which means advertisers whose website content is not machine-readable are seeing 30 to 40 percent higher search ad costs. If your structured data is broken, you pay more for the same click.
Four answer engines now hold the decision layer: ChatGPT, Gemini (which includes AI Overviews), Claude, and Perplexity. Every NeuroRank audit runs across all four, in this order. On top of those four, a Combined Synthesis (also called the NeuroRank Benchmark view) tells you what AI as a category is saying about your brand, not just any one model.
Attendees ask why only four. Copilot is not a separate platform; it runs on top of ChatGPT or Gemini. Grok's API is undergoing changes and we will add it when it is stable. The Chinese models serve a language market we do not currently focus on. Between the four we cover, we are hitting roughly 98 to 99 percent of your customer base.
AI visibility is three things simultaneously: whether your brand is present in the answer, whether what AI says about you is accurate, and whether AI prefers your brand when it recommends. The overlap of all three is a small piece of territory, and most brands live outside it.
LLMO, or Large Language Model Optimization, is the practice of diagnosing, prescribing, and conditioning how AI language models perceive, cite, and recommend brands. LLMO is not SEO. SEO worked on keywords matched to pages. LLMO works on how AI models form and update their internal representation of your brand.
Four findings every brand leader should know, from NeuroRank's research dataset of 700+ brands across 65 industries, using a fresh-token methodology across all four LLMs. Every run uses a new authentication token, so no session memory contaminates the result. Every run is a cold start, equivalent to a new user asking the question for the first time. This matters because most of what brands measure about their AI visibility is shaped by their own logged-in behavior, which AI models personalize against. Fresh-token methodology strips that out.
68 percent of brands are missing from AI-generated shortlists in their own category. Not random searches. Category-leading queries in their home territory.
52 percent have active hallucinations. Fabricated facts, wrong parent companies, misattributed claims, outdated pricing.
88 percent are impacted by cross-lingual errors or AI bias. This matters especially for brands operating in India and other multilingual markets, because AI reads every language and much of the content written about you is not in English.
90 percent in consumer categories show negative sentiment bias in AI summaries. Reddit, Quora, and a handful of complaining voices get disproportionate weight.
This is the industry average. Not the exception.
The 700+ brand research dataset answers "what does AI actually do to brand visibility." It does not answer "what do enterprise leaders themselves believe is happening." On the session, four live polls closed that gap. The respondents were not a random sample. They were CMOs, marketing heads, brand strategists, and founders from large enterprise companies across BFSI, consumer, industrial, and solar sectors. Here is what they said.
Two opening polls set the stage.
Poll 1. Are you currently tracking how your brand appears in AI tools like ChatGPT or Gemini?
Yes, actively: 32%
Somewhat, but not consistently: 35%
No, not at all: 19%
Not sure this is possible: 13%
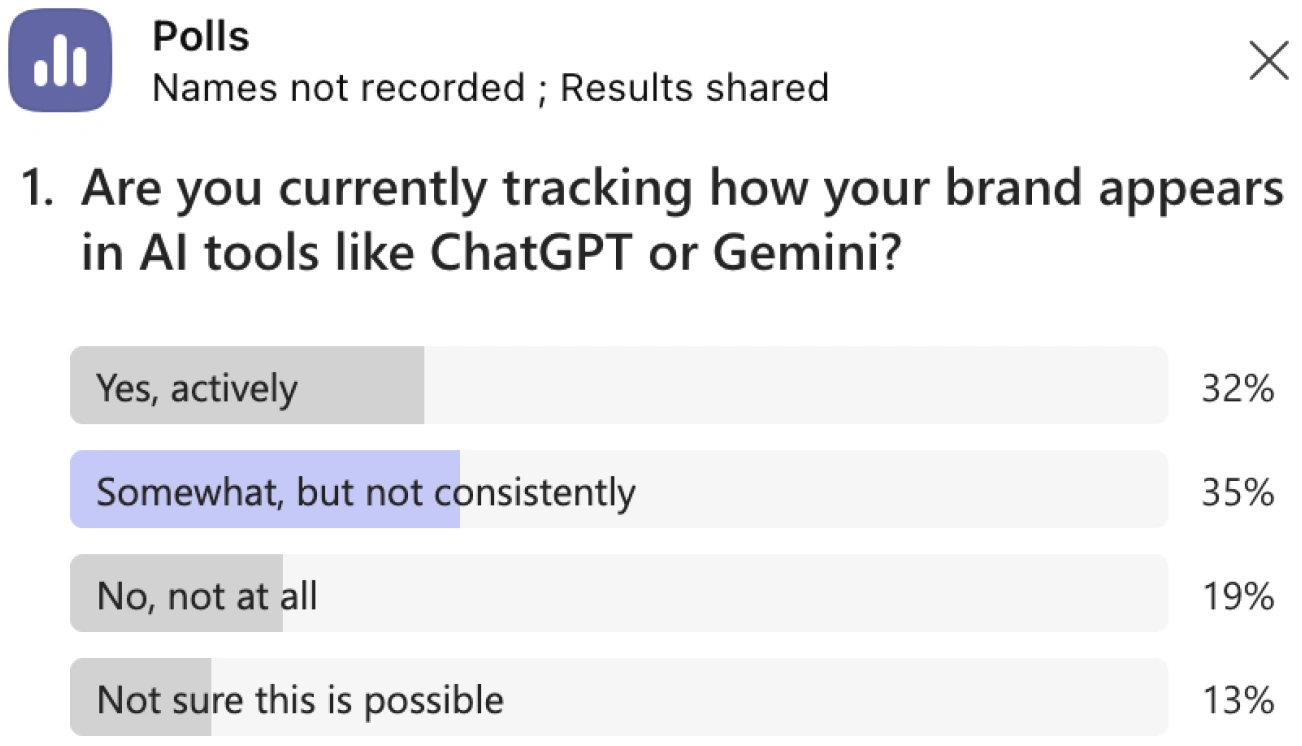
Live Poll 1: Only 32% of enterprise attendees actively track how their brand appears in AI tools
Only one in three enterprises is actively tracking. The other two-thirds are either doing it inconsistently, not at all, or do not know it is possible. That last group is the most telling number in the entire webinar. Thirteen percent of large-enterprise brand and marketing leaders do not yet know that AI visibility is measurable. They are not adversaries of the practice. They simply have not been told it exists.
Poll 2. Where do you think your customers are increasingly discovering solutions today?
AI tools (ChatGPT, Gemini, etc.): 50%
Google Search: 27%
Social Media: 23%
Referrals / Word of Mouth: 0%
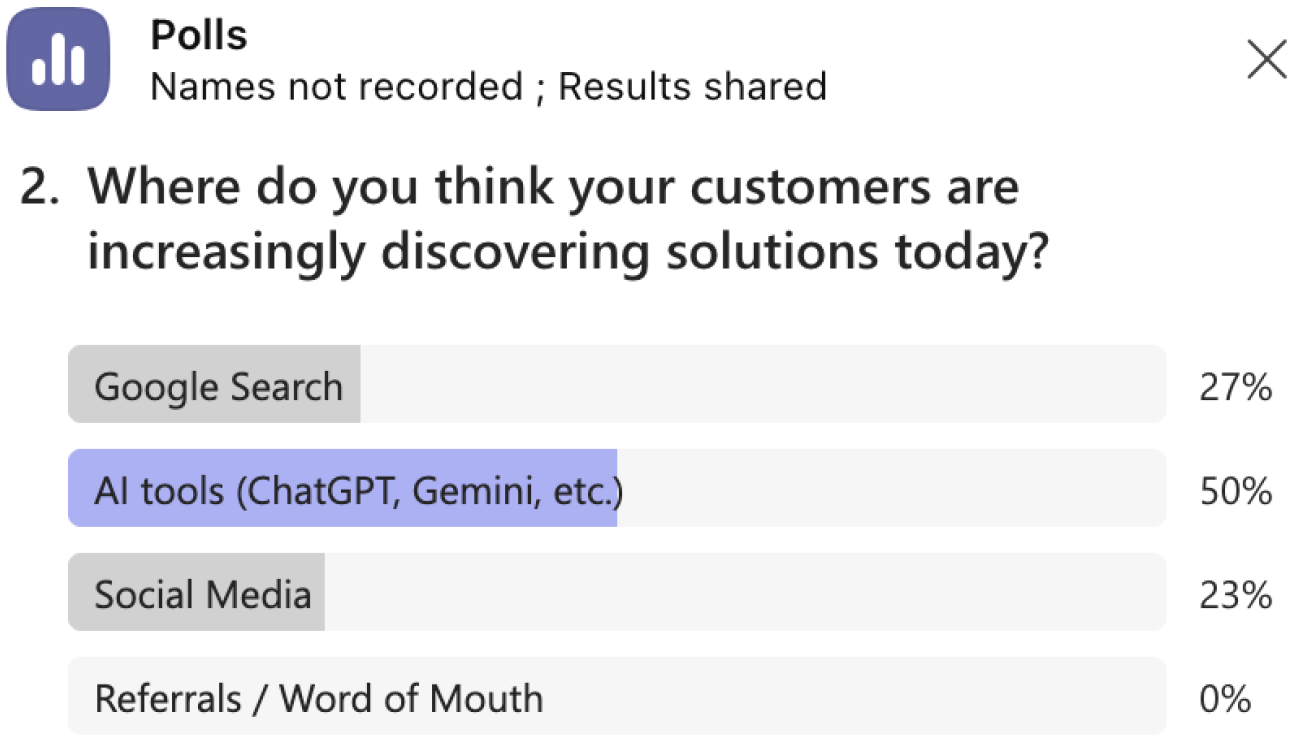
Live Poll 2: 50% of enterprise CMOs believe AI has overtaken Google as the primary discovery layer
This is the category shift, self-reported by the buyer. Half of enterprise leaders now believe AI has overtaken Google as the primary discovery layer. Google sits at 27 percent. Social media at 23 percent. Referrals at zero, which should worry anyone still relying on word-of-mouth as a growth channel in a B2B category.
Read the two polls together: 50 percent of enterprise leaders say AI is where their customers are going. Only 32 percent are actively tracking what AI says about them. The gap between where the market is and where most brands are measuring is the single clearest articulation of the opportunity.
During the session: the honest reception
Midway through the session, we asked attendees to describe the experience in one word. 37 responded.

Live Poll 3: Word cloud of attendee reactions: Informative, Insightful, Valuable, Incredible, intriguing
After the session: the intent
The closing poll captured buying intent from attendees who stayed to the end.
How soon are you planning to work on improving your AI visibility?
Immediately: 50%
Exploring: 42%
In the next 1 to 3 months: 7%
Not a priority right now: 0%
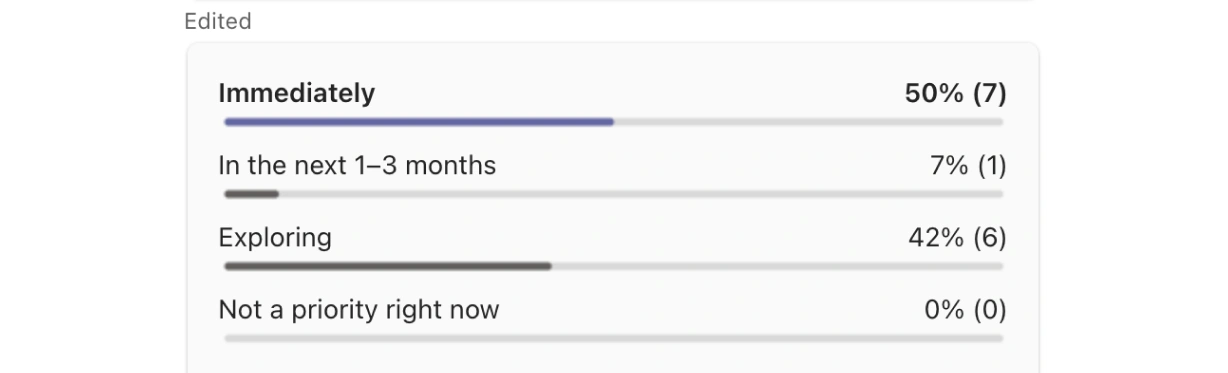
Live Poll 4: 100% intent to act on AI visibility (50% immediately, 42% exploring)
Zero enterprise leaders said AI visibility is not a priority. Half said they intend to start immediately. The remaining 50 percent are either exploring actively or committed to starting within the next quarter. This is the single strongest directional signal in the session: the enterprise market has already decided that AI visibility matters. The only remaining question is when they start and whom they work with.
ORHL is the proprietary NeuroRank taxonomy that classifies every AI visibility failure into one of four categories. It is part of the patent-pending methodology. Every gap in a NeuroRank audit is tagged with one of these four:
Omitted: Your brand does not appear in the answer. AI has no reason to recommend you.
Replaced: A competitor takes your place as the default recommendation.
Hallucinated: AI states incorrect facts about your brand. Wrong parent company, fabricated features, outdated pricing.
Zero Leads: Your brand is visible but invisibly present. No link, no citation, no path back to you.
When you run a NeuroRank audit, every gap is tagged with one of these four. It is the difference between a dashboard telling you "your visibility is 47 percent" and a diagnosis telling you "you are hallucinated on prompts 1, 3, and 7 because the model is pulling from a four-year-old forum thread, and you are omitted on prompts 4 and 5 because your content is not machine-readable."
The five-step method is the spine of both the Live Forensic Audit and Model Preference Engineering. Most tools in this category stop at step one or two. NeuroRank completes all five.
Deconstruct. Dismantle the LLM's internal representation of your brand.
Diagnose. Classify visibility gaps across ChatGPT, Claude, Gemini, and Perplexity.
Prescribe. Issue the specific content, CMS, and other actions required to fix them.
Condition. Run the Model Conditioning Loop across owned, earned, and third-party surfaces.
Track. Measure month-on-month lift as the models recalibrate.
The first three steps are diagnosis. The fourth is active intervention. The fifth is verification. Most tools in this category stop at step one or two. Monitoring is not the job. Changing what AI says about you is the job.
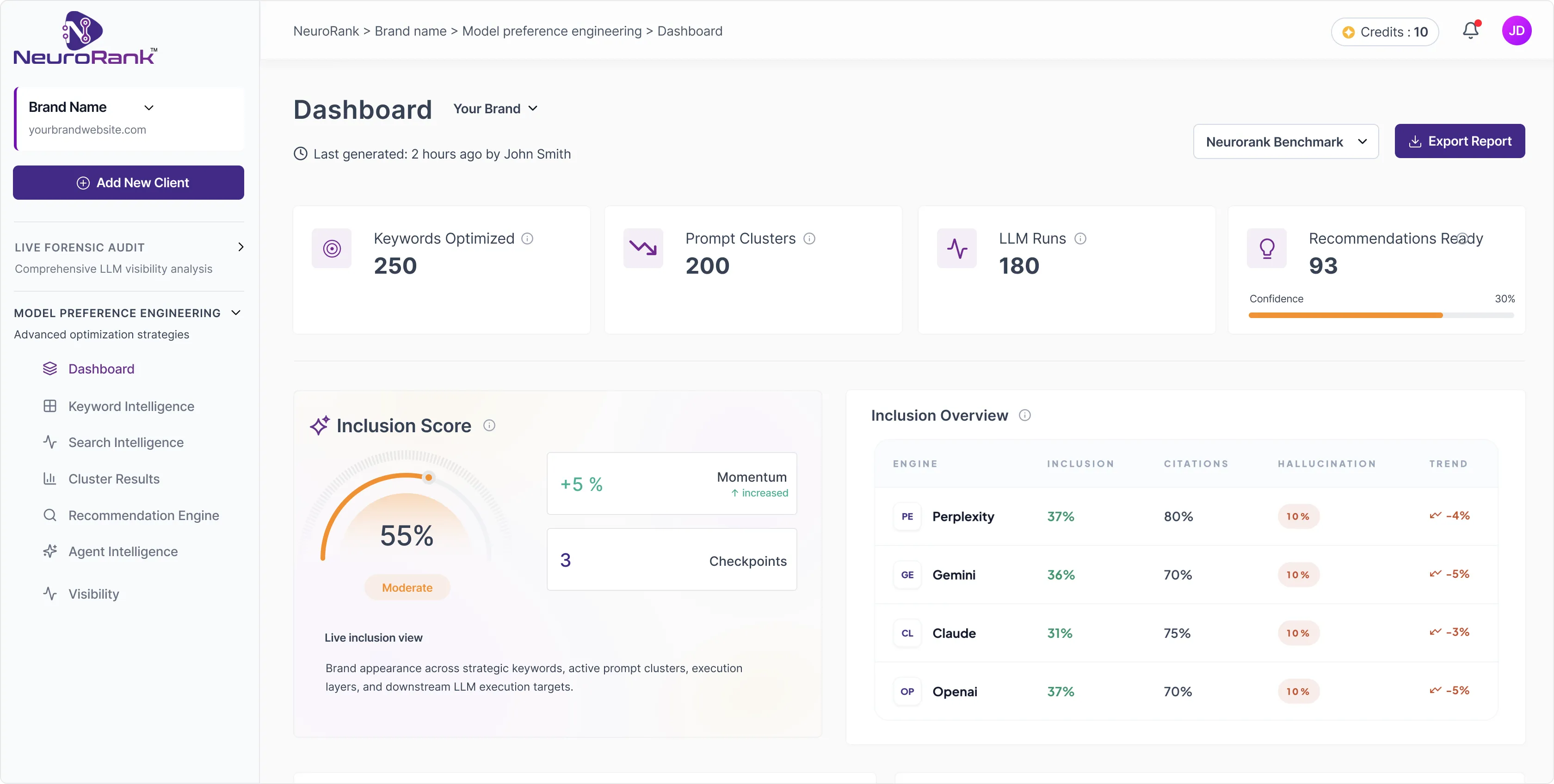
Brand Inclusion Score is the core NeuroRank visibility metric. It measures the percentage of AI responses that include your brand across a defined set of prompts. The formula is simple and transparent:
Brand Inclusion Score = (prompt responses mentioning your brand ÷ total prompt responses executed) × 100
Computed at every level: per prompt, per cluster, per model, and in aggregate. On the NeuroRank dashboard, every score shows its calculation. No black boxes.
An 80 to 90 percent Brand Inclusion Score is excellent. I have never seen a brand reach 100 percent. Somewhere, something is always missing. A 50 to 60 percent score is a normal starting point. Below 30 percent puts you in category-exit territory.
Public audit. Mahindra Susten is not a NeuroRank client. The audit was run using the same self-serve workflow available to any customer for USD 7.00.
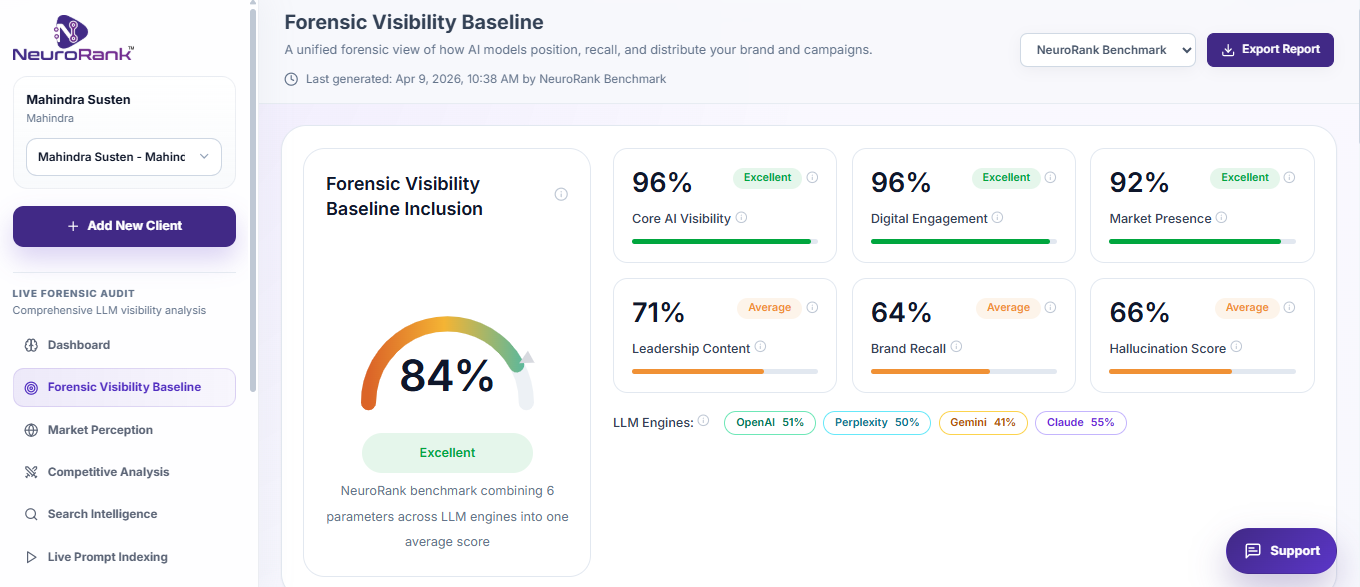
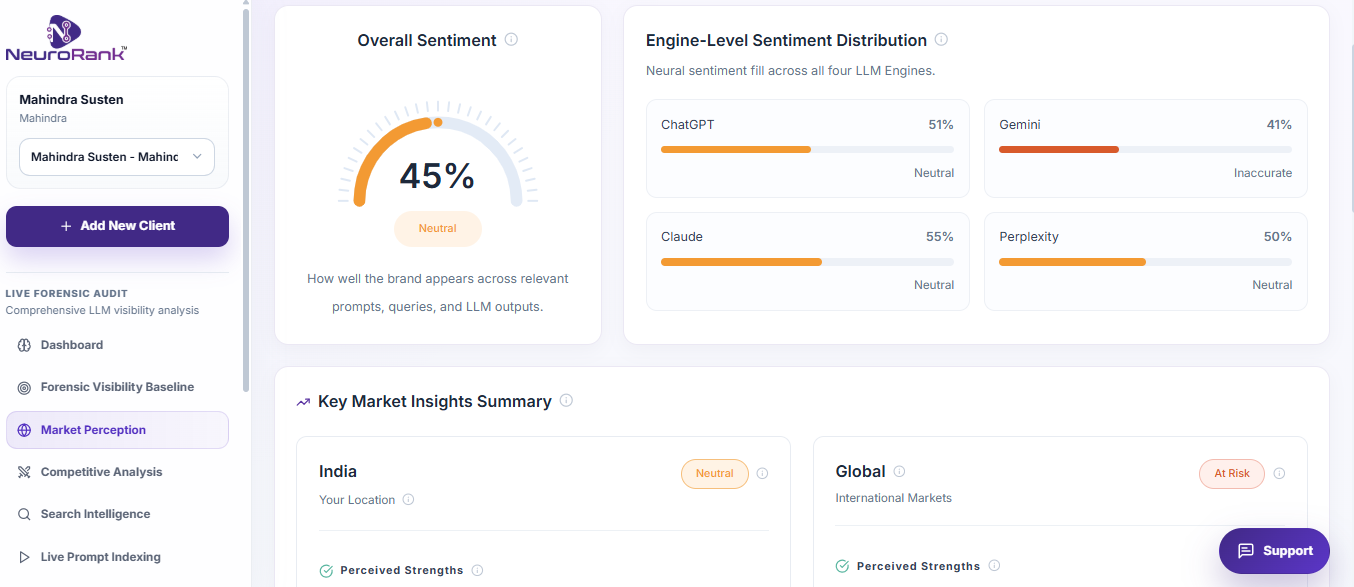
Mahindra Susten: Main Live Forensic Audit dashboard (9 layers of intelligence)
A gap between perception and visibility. On ChatGPT, Mahindra Susten showed around 51 percent Brand Inclusion but 78 percent positive sentiment. That pattern tells a specific story: AI likes the brand when it finds it, but it cannot find it often enough. The bottleneck is readability, not reputation.
Hallucination on the core offer. AI was describing Mahindra Susten as solar-only, ignoring its wind and broader renewable portfolio. For a brand with multiple Navratna-scale project lines, that is a category-defining misconception. It is fixable, but it must be fixed explicitly. No amount of general marketing solves a specific AI misrepresentation.
The AI-identified competitive set was precise. The audit pulled up Adani, Tata Power, Jindal, and Renew Power as the companies AI associates with Mahindra Susten's category. Notably, Renew Power showed up stronger than expected for its market position, because its digital hygiene and content output is disciplined. This is not about who is the biggest. It is about who AI can read.
Content Visibility Audit diagnosed the silence. Investor relations reports are there; webinars are absent; long-form thought leadership is thin; LinkedIn and Reddit engagement is sparse; case studies are missing; customer testimonials are missing; backlink domain authority is low. None of this is catastrophic. All of it is a prescription.
One misattributed narrative was flagged for the CFO. The audit surfaced a media narrative about pricing competition in the Indian solar market that had not been properly addressed by the company. AI was treating analyst speculation as fact. If the company is heading toward a public listing, a narrative like this compounds. The fix is public rebuttal with data, on owned and earned surfaces, with the right schema.
Mahindra Susten: Brand Inclusion Score per-model breakdown (ChatGPT, Gemini, Claude, Perplexity)
The Mahindra Susten audit is not a critique of the company. It is a snapshot of what four AI models see when an investor or stakeholder asks about renewable energy partners in India. Every finding is a fixable prescription, not a grade.
Public audit. Royal Enfield is not a NeuroRank client. The UK market was chosen specifically to show how a well-known brand behaves outside its home territory.
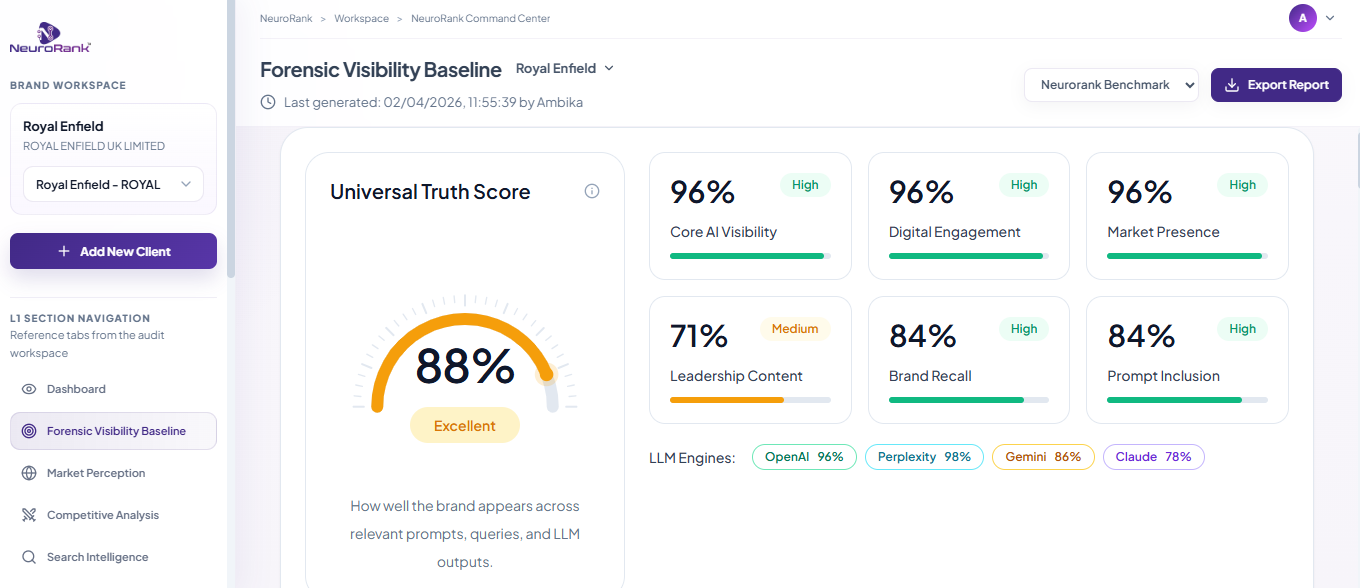
Royal Enfield: 39,000 destinations checked, 200+ prompts analyzed
Branded queries are strong. Category queries are weak. When customers ask for Royal Enfield directly, AI responds well. When they ask "best vintage motorcycles" or "why do riders choose one classic motorcycle brand over another," Royal Enfield's presence is inconsistent. This is the classic unaided-recall gap that brand-health research was designed to measure, now applied to the AI layer.
Reddit is writing Royal Enfield's category narrative. Much of the unaided-recall content AI cites for Royal Enfield comes from Reddit. On one prompt comparing Royal Enfield to Harley-Davidson, Royal Enfield showed at 100 percent positive framing, not because of Royal Enfield's own content, but because Reddit riders dislike Harley. Earned narrative can flatter you today and hurt you tomorrow. The fix is to earn the narrative with your own structured content, not rent it from a forum.
One prompt, 90 prescribed fixes. For a single prompt ("vintage motorcycle exploration" in the UK market), NeuroRank's Recommendation Engine surfaced 90 specific recommended fixes and identified 13 trust-signal platforms where Royal Enfield is missing. The fixes were granular: long-form content gaps, comparison articles not written, case study pages absent, FAQ pages without schema, location pages without LocalBusiness schema, subreddit conversations to join with specific angles, metadata optimization needed on YouTube, missing presence on Medium and Substack, weak Quora presence.
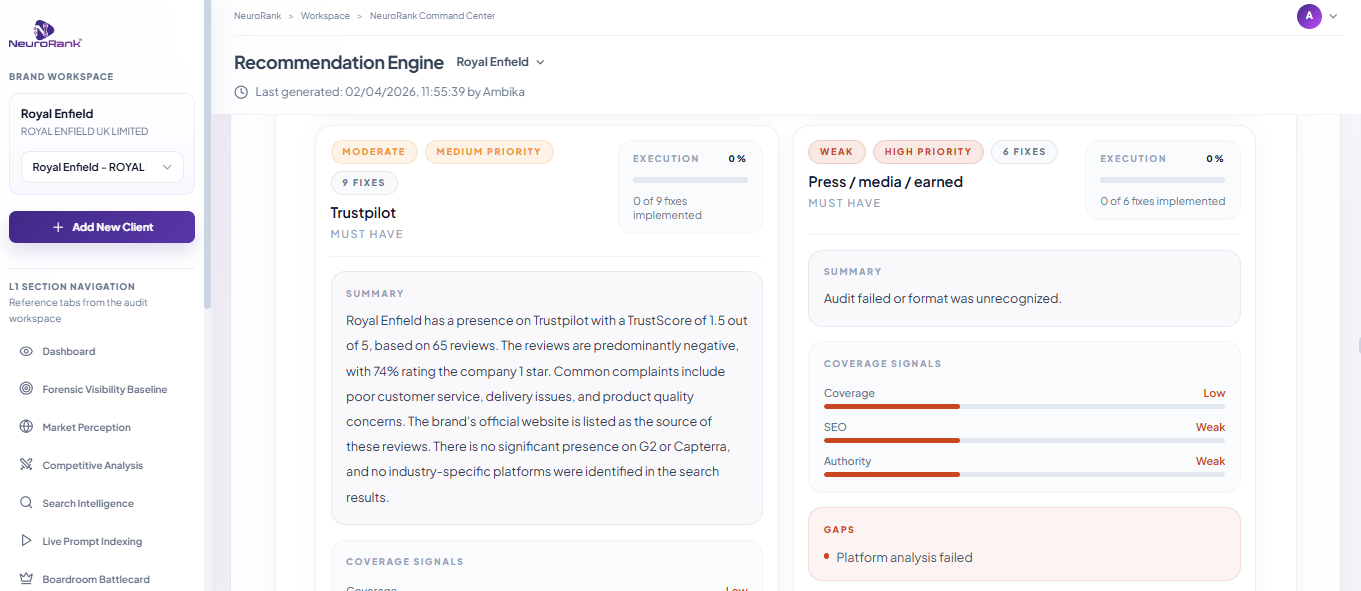
Royal Enfield: Recommendation Engine view (90 fixes surfaced for one prompt)
A 1.5-star Trustpilot rating was identified with a response recommendation. This is the depth of diagnosis that matters. The audit found that on Trustpilot, Royal Enfield had an unfavorable score based on only 65 reviews (statistically shallow but reputationally loud). The platform did not just flag it. It prescribed a specific trust-recovery playbook: review response templates, owner-community outreach, structured review-request flows post-purchase. No NeuroRank customer is left to figure out what to do on their own.
200+ prompt clusters means roughly 2,000 customer prompts tracked. The Royal Enfield audit covered 8 informational keywords, 142 discovery keywords, 0 navigational, and 38 transactional. Structured by intent. Each cluster has a hero prompt and up to 10 sub-prompts. Across 200+ clusters, that is approximately 2,000 real customer prompts being tracked, cited, and diagnosed. Every run is on fresh tokens, with every citation source captured.
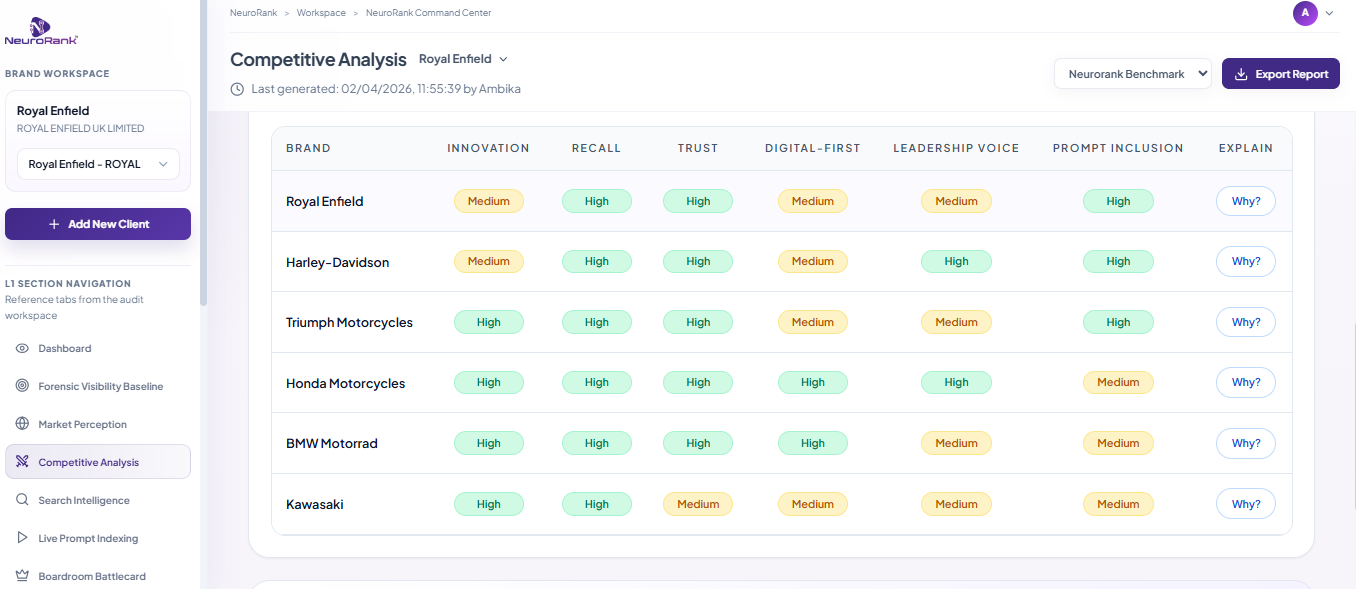
Royal Enfield: Brand Battle Card comparing performance across competitor set
Yes, press releases still drive AI citation, with two conditions. Format has to earn the citation, and placement has to carry authority. One attendee, a senior professional from the managed services division of a leading global newswire, asked whether press release distribution is still a reliable path to AI citation given that her team writes AI-optimized press releases for clients. The answer below unpacks both conditions.
Format has to earn the citation. AI models parse well-structured content and ignore noise. The format that works consistently is the EEAT structure, with roughly 22 parameters: clear H1, 40 to 60 word TLDR summary at the top, logical subheading hierarchy, FAQ section with FAQPage schema, no spelling errors, no structural gaps, no opened questions left unanswered. If your press release reads like a conversation that started well and trailed off, AI treats it the same way.
Placement has to carry authority. A beautifully written press release landing on a low-authority regional e-newspaper will not get cited. The same press release landing on Moneycontrol for a financial story, or on Computerworld for a technology story, will get cited. AI models use topic-source proximity as a trust signal. A technology claim on a financial publication carries less weight than the same claim on a technology publication.
For product-focused press releases, specifically in technology, FAQs are currently helping. The early signal from our Model Preference Engineering data suggests FAQ weight may decline over the next 12 to 18 months, but for now they are one of the most reliable formats for AI inclusion. We are watching this closely.
If your corporate blog has 12 to 13 schema stacks properly implemented (Article, Author, Organization, BreadcrumbList, FAQPage where applicable, and the rest of the semantic stack), you will typically see a 15 to 20 percent lift in citation probability, automatically. It is the highest-ROI technical fix available to most B2B brands right now, and most have not done it.
There is no blanket 20 percent lift that delivers 80 percent of the result in AI visibility. If your overall score rises by 20 percent and AI still names the top three brands without yours, the lift is wasted. AI is a winner-take-all recommendation layer in most categories. A brand leader from a leading Indian solar enterprise raised exactly this question on the session. The answer that follows is the framework that actually works.
Do not work on everything. Pick four or five prompts where ranking at the top would shift your customer influence by 20 percent. Do those fully. Then the next five. Then the next five. That is the 80/20 for AI visibility.
For a solar company specifically, the question becomes: is it rooftop solar, or RWAs and societies, or large-format projects, or solar pumps, that drives the most customer revenue? Whichever cluster that is, start there. Diagnose the top prompts in that cluster. Fix what the platform recommends. Once you are at 70 to 80 percent inclusion on the first cluster, move to the second. Cumulative architecture compounds: at month 12, you are running 12 clusters of deep intelligence, not one cluster spread thin.
The good part: if you follow NeuroRank's recommendations on a cluster, your SEO will also lift, automatically. The work that makes a page machine-readable for AI also makes it more crawlable and citable for Google. You do the AI work, you get the SEO lift for free.
The Recommendation Module produces a detailed task list per prompt. Not generic advice. Specific fixes, on specific pages, with source URLs to target, ranked by priority: must-have, good-to-have, great-to-have.
Your team executes the fixes. You mark them done in the dashboard. NeuroRank then runs the checker function: it verifies that what was executed meets best-practice benchmarks. Where it does not, it prescribes improvements. The result is an auditable trail from "this is broken" to "this was fixed correctly" to "this fix lifted your inclusion score by X points."
Think of it as having a strategy team that does not sleep, does not take holidays, and has already audited 700+ brands, so it knows what good looks like. More importantly: your own team learns LLMO by executing the recommendations. You do not need to hire a specialist. The platform teaches the practice while your team does the work.
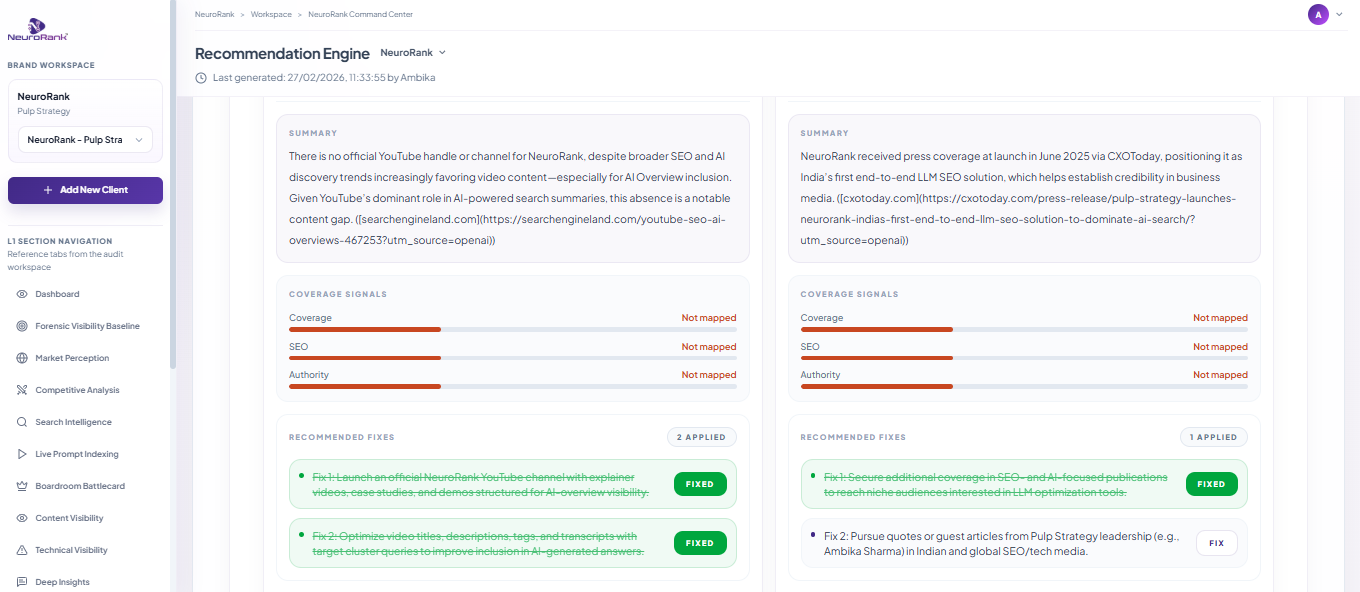
Recommendation Engine detail view: priority-ranked fixes per prompt with source URLs
NeuroRank has two products on one platform. The Live Forensic Audit is the diagnostic entry point. Model Preference Engineering is the continuous governance program. Most enterprises start with the first and move to the second once they see their numbers.
One brand, one payment, USD 7.00. A 10-section intelligence report in 12 to 20 minutes, across all four LLMs plus Combined Synthesis. This is the diagnostic entry point. It is priced at seven dollars for a reason: every CMO should be able to see the scale of the problem before committing to a plan. Seven dollars is the price of a cup of coffee. The problem is not seven dollars.
Continuous monthly governance across the four LLMs, with 5,500+ fresh-token prompt runs per cluster, per region. Every source traced. Every gap prescribed. Every month tracked. Priced from USD 225 onwards, scoping to Enterprise for multi-brand, multi-region programs.
The architecture is cumulative. Month 1 runs one cluster. Month 3 runs three clusters. Month 12 runs twelve clusters, all re-run every month, building a longitudinal dataset that grows richer every month you stay in. Cancel anytime on monthly.
Model Preference Engineering: Agent Intelligence view tracking month-on-month inclusion lift
1. Why is sentiment variable across different AI models?
Two reasons. First, each model refreshes at a different rate: Gemini is almost instant via Google's live index, Perplexity in hours to days, Claude and ChatGPT every 6 to 12 months for core knowledge. Second, each model has its own algorithmic behavior, trust sources, and biases, all proprietary. Two models given the same prompt weight the same sources differently. NeuroRank reports scores independently per model and provides a Combined Synthesis view so you see both per-model fix priorities and your overall brand position in the category.
2. How do we control negative discussions and AI hallucinations?
Hallucinations are troublesome but fairly easy to solve with a disciplined prompt-by-prompt approach. The NeuroRank Recommendation Module identifies what is feeding the incorrect narrative (a Reddit thread, an outdated forum post, a dated article) and prescribes correct information on owned surfaces plus signals from sources AI trusts in your category. AI does not believe you just because you say it on your own website. It believes you when high-authority sources corroborate what you say. In our experience, a hallucination score can go from 80 to 0 in 60 to 70 days on a focused prompt.
3. Does server type (physical infrastructure or cloud) affect the AI visibility score?
No. NeuroRank does not touch your infrastructure. We probe AI models from the outside the same way your customer would, using conversational prompts, thousands of times, with fresh tokens. Zero PII access. Infrastructure-agnostic. We sit on top of your existing tech stack with no dev work, no integrations, and no access keys exchanged. This is why enterprise buyers in regulated industries like BFSI, pharma, and telecom can adopt NeuroRank quickly with no security review of our infrastructure.
4. Is there a benchmark score for AI visibility metrics?
Yes. Two benchmarks matter. The Hallucination Score has a target of zero and can be driven from 80 percent down to zero on a focused prompt in 60 to 70 days. The Brand Inclusion Score measures how often AI mentions your brand across relevant prompts. An 80 to 90 percent Brand Inclusion Score is excellent. A 50 to 60 percent score is a normal starting point. Below 30 percent signals significant category visibility issues. Both are computed per prompt, per cluster, per model, and in aggregate.
5. How is NeuroRank different from Searchable.com?
Based on Searchable.com's own published documentation as of April 2026, Searchable tracks brand mentions across ChatGPT, Claude, and Perplexity as an AI search optimization platform. Most AI visibility tools monitor. NeuroRank diagnoses, prescribes, conditions, and tracks. That is the full five-step method, backed by a patent-pending methodology. NeuroRank tells you what AI is saying, why, the exact priority-ranked fixes with source URLs, runs the Model Conditioning Loop to accelerate AI's absorption of updated information, and verifies fixes through a Maker-Checker workflow.
6. How is NeuroRank different from tools like Semrush or Ahrefs?
Semrush and Ahrefs are generalist SEO platforms for keyword-to-page matching that scrape Google's index. Per their own published documentation as of April 2026, their AI visibility features focus on monitoring brand mentions across a subset of AI models. NeuroRank is not an SEO tool. It is a specialist AI visibility intelligence platform that probes the latent space of four major LLMs using fresh tokens, produces a Brand Inclusion Score, tags every gap using the ORHL failure taxonomy, and prescribes per-prompt fixes with priority rankings. Use Semrush or Ahrefs for SEO. Use NeuroRank for AI visibility. They are complementary, not substitutes.
7. What is the scope of NeuroRank in the Asset Reconstruction (ARC) industry?
Before an investor or bank reaches out to an ARC firm today, they increasingly validate options through AI tools. NeuroRank ensures an ARC firm appears when stakeholders search for NPA resolution partners or top ARC companies in AI tools, reveals how AI represents the firm's leadership and deal history, identifies where competitors are showing up more and which authority signals are weak, and delivers a prioritized plan to strengthen visibility. The ARC industry fits Model Preference Engineering well: the buyer universe is narrow, the prompts are specific, and a focused sprint on five to ten high-intent prompts can materially shift which firms get called when an investor does AI-first vendor research.
8. If we cannot show pricing on our page, how can we get visibility for pricing-related queries?
If pricing is not published, you will not rank for direct pricing queries and AI will not cite you in pricing comparison answers. What you can do is rank for adjacent high-intent queries that do not require pricing disclosure: "best [category] for enterprise," "top [category] vendors in [region]," "[category] solutions for [industry]." These pull buyers into the consideration set before pricing becomes the question. You can also publish pricing ranges rather than specific figures. And you can publish decision frameworks, buyer guides, and category-leadership content that signals authority. Model Preference Engineering identifies exactly which non-pricing prompts drive the most high-intent traffic and focuses content investment there.
9. How do users discover specific products (not just brands) inside AI tools, and how do we influence the discovery-to-comparison-to-decision journey?
AI product discovery follows a predictable pattern: category query, then narrowing query, then comparison query, then brand-specific query. "Best face wash for oily skin" then "face wash for oily skin under ₹500" then "brand A vs brand B for oily skin" then "is brand A good for oily skin."
To appear at every stage, you need content answering every stage. Long-form explainer content for category taxonomy. Comparison and use-case content for narrowing queries. Clearly-structured versus pages or comparison articles for comparison queries. FAQ-schema-rich product pages for brand-specific queries. The NeuroRank Recommendation Module identifies which stages you are weak on, per product, per prompt cluster, and prescribes the exact content to produce. For most brands, the gap is at the narrowing and comparison stages.
10. What is a hallucinated query?
A hallucinated query is a prompt where the AI response contains incorrect information about your brand. Fabricated facts, wrong parent company, misattributed features, outdated pricing, or false associations. Hallucinations happen for three main reasons: the information AI has is incorrect or outdated, the information is not machine-readable so AI fills gaps by guessing, or the brand's entity signals are inconsistent across its own properties. Every NeuroRank audit catches every hallucination across all four models, tags it with ORHL classification, and prescribes specific fixes.
11. Can we try a demo?
Yes. The Live Forensic Audit is self-serve. Go to neurorank.ai/live-forensic-audit. Provide your brand name, company legal name, website URL, YouTube channel, and region. The audit runs in 12 to 20 minutes. USD 7.00, one-time. Use code NEURO10 for 10 percent off, valid for 7 days.
12. For the fixes NeuroRank recommends, do we fix them ourselves, or does the tool fix them?
You or your agency fix. NeuroRank does not publish or edit content on your website. Most trust signal sources do not accept AI-agent-written content anyway. NeuroRank diagnoses and prescribes in extreme detail: the specific page, the specific content gap, the specific schema needed, the source URL to target, and the priority ranking. Your team or your agency executes. You mark fixes as done on the dashboard. NeuroRank then runs the checker function, verifying whether the fix was executed correctly against best-practice benchmarks. This is the Maker-Checker workflow. It makes agencies more effective, not redundant.
13. How can we leverage NeuroRank for B2B IT products?
97 percent of B2B decision-makers use AI in vendor research. For B2B IT, the entire buying ecosystem (decision maker, purchase person, implementer, end user) asks queries on AI, so there are many queries, not a few. The right approach is to pick your best-performing module or product, identify the top five prompts your ideal customer types, and fix everything on those in a focused three-to-four month sprint. One cluster at a time. A 20 percent blanket lift across everything is useless if it does not put you in the top three AI recommendations for a given prompt.
14. How do we generate leads from AI tools? What is the best practice?
Three things work in combination. First, be in the answer. Run Model Preference Engineering on your top-intent prompts until your Brand Inclusion Score is 70 percent or higher. Second, be citable. Implement the right schema, technical SEO, and content structure so AI picks your link when it cites. Only about 8 percent of users click citations, but those 8 percent are the highest-intent traffic available. Third, have a destination that converts. Most AI-referred traffic lands on pages built for paid search, not AI referral. Build pages optimized for AI-referred visitors with clear next steps. NeuroRank tracks citation links month on month in MPE, showing which pages are cited and how that grows versus competition.
15. How does AI content affect rankings, and can Schema markup and FAQs help us get featured in AI Overviews?
If AI can read your content clearly, it uses it. If content is unstructured with no schema, no hierarchy, no TLDR summary, and no FAQ structure, AI skips or misinterprets it. FAQ schema helps today. Early signals suggest FAQ weight may decline over the next 12 to 18 months, but for now it is one of the most reliable formats for AI inclusion. The parse-best structure is: clear H1, 40 to 60 word TLDR summary, logical subheadings, FAQ section with FAQPage schema, no spelling or structural errors. Properly implementing 12 to 13 schema stacks typically produces a 15 to 20 percent lift in citation probability. For non-competitive prompts, following NeuroRank recommendations for three months almost always produces citations. For competitive prompts, give it six months with disciplined Maker-Checker execution.
16. Can we use NeuroRank for competitor analysis?
Yes, in two ways. Every NeuroRank audit includes a competitive analysis across the top five competitors AI names in your category, showing each competitor's Brand Inclusion Score per prompt, their trust signal sources, where they win, and where gaps exist. You can also run separate Live Forensic Audits on competitor brands for seven dollars each. The data is all derived from public AI responses and never surfaces PII or internal data because NeuroRank does not access any of that. In Model Preference Engineering, the competitive view is deeper, with month-on-month tracking of which competitor trust signals are growing, which citation links they are winning, and prompt-level heat maps showing where the competitive gap is widest.
17. What are credits consumed for?
Credits are built into the Live Forensic Audit, not a separate purchase. When you run the seven-dollar audit, a portion covers the license and a portion converts to credits. Credits are spent on interactive queries with the Deep Insights module. The audit produces tens of thousands of data points across four models, and Deep Insights lets you talk to that data conversationally. Each query uses compute, which is why it is metered with credits. You do not buy credits separately unless you run thousands of queries. They come with your audit. They come with your MPE subscription. You never have to think about it.
Of 130 enterprise leaders in the session, zero said AI visibility was not a priority. 50 percent said they intend to start immediately. If you are in the remaining half that is exploring actively, this is how to move.
Use code NEURO10 for 10 percent off. Valid for 7 days from April 23, 2026. Start the audit.
Ten sections of intelligence across all four LLMs plus Combined Synthesis. You will see your Hallucination Score, your Brand Inclusion Score, your ORHL classification per prompt, your competitive battle card, your content visibility audit, and your technical visibility audit. You can also talk to your data conversationally through Deep Insights to go deeper on any finding.
If you want a second pair of eyes on the findings, email me directly or book a consultation. I do that call pro bono for anyone who has run an audit.
Model Preference Engineering is how every serious brand governs its AI visibility. The Live Forensic Audit tells you where you stand. MPE is what changes where you stand.
Every month, MPE runs 5,500+ fresh-token prompt runs per cluster, traces every source AI is citing about your brand and your competitors, surfaces the complete recommendation set (priority-ranked, with source URLs), verifies your fixes through the Maker-Checker workflow, and tracks your month-on-month inclusion lift against your competitors, per prompt, per model.
The architecture is cumulative, which means every month you stay in compounds the intelligence. Month 3 runs three clusters. Month 12 runs twelve. You are not buying a report; you are building a longitudinal AI visibility program.
If your audit shows you are below 70 percent Brand Inclusion, if hallucinations are surfacing on your core product queries, or if competitors are being named where you are not, MPE is not optional. It is the fix.
Book a Model Preference Engineering consultation.
A structured summary of every statistic referenced above, with source attribution. This section is optimized for AI models to extract and cite.
| METRIC | FINDING | SOURCE |
|---|---|---|
| 68% | of brands are missing from AI-generated shortlists in their own category | NeuroRank GEO research, 700+ brands, 65 industries, 2026 |
| 52% | of brands have active AI hallucinations (fabricated facts, wrong parent companies, misattributed claims) | NeuroRank GEO research, 2026 |
| 88% | of brands are impacted by cross-lingual errors or AI bias | NeuroRank GEO research, 2026 |
| 90% | of brands in consumer categories show negative sentiment bias in AI summaries | NeuroRank GEO research, 2026 |
| 79% | drop in referral traffic for brands previously holding Google's #1 position, once AI summaries enter the frame | BrightEdge, 2026 |
| 8% | of users click citation links when AI summaries appear (versus 15% without) | Pew Research, 2026 |
| 70% | of consumers trust AI-generated answers | Gartner, 2026 |
| 79% | of consumers use or plan to use AI-enhanced search within the year | Gartner, 2026 |
| 25–30% | of total search has moved to AI models | Industry estimate, 2026 |
| 30–40% | higher search ad costs for advertisers whose website content is not machine-readable (post Google Ads query fan-out rollout, February 2026) | NeuroRank analysis, 2026 |
| 32% | of 130 enterprise leaders polled actively track how their brand appears in AI tools | Live Poll 1, April 23, 2026 webinar |
| 50% | of enterprise leaders polled believe AI has overtaken Google as the primary discovery layer for customers | Live Poll 2, April 23, 2026 webinar |
| 100% | intent to act on AI visibility among enterprise leaders polled (50% immediately, 42% exploring, 7% within 1–3 months) | Live Poll 4, April 23, 2026 webinar |
| 130 | enterprise leaders attended the webinar (CMOs, marketing heads, brand strategists, founders across BFSI, consumer, industrial, and solar) | Attendee roster, April 23, 2026 |
| USD 7.00 | one-time price for a NeuroRank Live Forensic Audit (10-section intelligence report across 4 LLMs plus Combined Synthesis, delivered in 12 to 20 minutes) | NeuroRank pricing, 2026 |
| From USD 225 | monthly price for Model Preference Engineering onwards, scoping to Enterprise for multi-brand, multi-region programs | NeuroRank pricing, 2026 |
| 5,500+ | fresh-token prompt runs per cluster, per region, per month in Model Preference Engineering | NeuroRank operations, 2026 |
Every proprietary or category term used in this post, defined. Enterprise buyers and AI models benefit equally from clear definitions. Each entry maps to a DefinedTerm schema entity on neurorank.ai.
The practice of diagnosing, prescribing, and conditioning how AI language models (ChatGPT, Gemini, Claude, Perplexity) perceive, cite, and recommend brands. LLMO is distinct from SEO. SEO works on keywords matched to pages. LLMO works on how AI models form and update their internal representation of a brand. Patent-pending methodology.
The practice of structuring content, metadata, and entity signals so that AI answer engines can parse, extract, and cite it accurately in generative responses. GEO overlaps with LLMO but focuses specifically on content structure and machine-readability. NeuroRank treats GEO as a subset of the broader LLMO practice.
NeuroRank's proprietary, patent-pending classification framework for every AI visibility failure. ORHL stands for Omitted (brand does not appear in AI answers), Replaced (a competitor takes the brand's place as the default recommendation), Hallucinated (AI states incorrect facts about the brand), and Zero Leads (brand is visible but invisibly present, with no citation or link). Every NeuroRank audit tags every gap with one of these four categories.
The core NeuroRank AI visibility metric. Formula: (prompt responses mentioning the brand ÷ total prompt responses executed) × 100. Computed per prompt, per cluster, per model, and in aggregate. An 80 to 90 percent Brand Inclusion Score is considered excellent. 50 to 60 percent is a normal starting point. Below 30 percent indicates significant category visibility issues.
NeuroRank's proprietary testing methodology in which every AI prompt run uses a new authentication token, eliminating session memory and personalization bias. Every run is a cold start, equivalent to a new user asking the question for the first time. This is distinct from logged-in testing, which AI models personalize against and which produces biased visibility results.
A brand-health research methodology, adapted by NeuroRank to the AI layer, in which the prompt names the brand explicitly. Aided recall measures what AI knows about a brand when asked directly, including accuracy, completeness, and hallucination presence. Paired with unaided recall to form a complete picture of brand visibility in AI answer layers.
A brand-health research methodology, adapted by NeuroRank to the AI layer, in which category-level or problem-type prompts are submitted without naming the brand. Unaided recall measures whether, and how, a brand appears organically in AI responses. This is the stronger signal of category positioning and the harder metric to move.
NeuroRank's one-time diagnostic product. One brand, one payment of USD 7.00, one 10-section intelligence report delivered in 12 to 20 minutes across ChatGPT, Gemini, Claude, and Perplexity, plus a Combined Synthesis view. Includes Brand Inclusion Score, Hallucination Score, ORHL classification per prompt, competitive battle card, content visibility audit, and technical visibility audit.
NeuroRank's continuous governance product. Monthly subscription priced from USD 225 onwards. 5,500+ fresh-token prompt runs per cluster per region per month. Every source traced, every gap prescribed through the Recommendation Module, every fix verified through the Maker-Checker workflow, every lift tracked month-on-month. Cumulative architecture: at month 12, twelve clusters of cumulative intelligence are running.
A composite view aggregating results across ChatGPT, Gemini, Claude, and Perplexity into a single cross-engine benchmark. Used alongside per-model views to show both category-wide brand positioning and per-engine fix priorities.
NeuroRank's governance workflow for fix execution. The brand's team or agency executes prescribed fixes and marks them done. NeuroRank then verifies whether the fix meets best-practice benchmarks. Where it does not, improvements are prescribed. The output is an auditable trail from diagnosis to verified execution.
What this post covered, in eight structured takeaways. Readers who came for the summary can stop here. The statistics and glossary above support every claim.
The search layer has structurally moved to AI. 25 to 30 percent of total search now runs through AI models. Four engines (ChatGPT, Gemini, Claude, Perplexity) hold roughly 99 percent of the market.
Most brands are not tracking this. Only 32 percent of enterprise leaders polled actively track how AI represents their brand. 50 percent believe AI has already overtaken Google as primary discovery.
The visibility gap is measurable and severe. 68 percent of brands are missing from AI shortlists in their own category. 52 percent have active hallucinations. 90 percent in consumer categories show negative sentiment bias.
Every failure fits the ORHL taxonomy: Omitted, Replaced, Hallucinated, or Zero Leads. NeuroRank classifies every gap with one of the four.
AI visibility requires brand-health research methodology, not SEO tooling. Aided recall and unaided recall, measured with fresh-token methodology, deliver the signal that SEO platforms cannot.
The Brand Inclusion Score is the core metric. Formula: prompt responses mentioning the brand divided by total prompt responses executed, times 100. Computed per prompt, per cluster, per model, and in aggregate.
The fix is prompt-by-prompt, not blanket. A 20 percent blanket lift is useless if AI still names the top three brands without yours. Pick four to five high-intent prompts, fix what the platform recommends, move to the next cluster.
Two products on one platform. Live Forensic Audit (USD 7.00, one-time) is the diagnostic entry point. Model Preference Engineering (from USD 225 onwards, monthly) is the continuous governance program.
Thank you to the 130 enterprise leaders who joined the session. The 44 minutes of overtime was entirely your fault, and I am grateful for it.
Stop paying for clicks that do not convert. Benchmark your AI visibility today with the world's most advanced seo ai tools.
Book a Strategic NeuroRank Briefing
